
Функция ФИШЕР выполняет возвращение преобразования Фишера для аргументов X . Это преобразование строит функцию, которая имеет нормальное, а не асимметричное распределение. Используется функция ФИШЕР для того чтобы проверить гипотезу с помощью коэффициента корреляции.
Описание работы функции ФИШЕР в Excel
При работе с данной функцией необходимо задать значение переменной. Сразу стоит отметить, что существуют некоторые ситуации, при которых данная функция не будет выдавать результатов. Это возможно, если переменная:
- не является числом. В такой ситуации функция ФИШЕР осуществит возвращение значения ошибки #ЗНАЧ!;
- имеет значение либо меньше -1, либо больше 1. В данном случае функция ФИШЕР возвратит значение ошибки #ЧИСЛО!.
Уравнение, которое используется для математического описания функции ФИШЕР, имеет вид:
Z"=1/2*ln(1+x)/(1-x)
Рассмотрим применение данной функции на 3-x конкретных примерах.
Оценка взаимосвязи прибыли и затрат по функции ФИШЕР
Пример 1. Используя данные об активности коммерческих организаций, требуется сделать оценку связи прибыли Y (млн руб.) и затрат X (млн руб.), используемых для разработки продукции (приведены в таблице 1).
Таблица 1 – Исходные данные:
| № | X | Y |
| 1 | 210 000 000,00 ₽ | 95 000 000,00 ₽ |
| 2 | 1 068 000 000,00 ₽ | 76 000 000,00 ₽ |
| 3 | 1 005 000 000,00 ₽ | 78 000 000,00 ₽ |
| 4 | 610 000 000,00 ₽ | 89 000 000,00 ₽ |
| 5 | 768 000 000,00 ₽ | 77 000 000,00 ₽ |
| 6 | 799 000 000,00 ₽ | 85 000 000,00 ₽ |
Схема решения таких задач выглядит следующим образом:
- Рассчитывается линейный коэффициент корреляции r xy ;
- Проверяется значимость линейного коэффициента корреляции на основе t-критерия Стьюдента. При этом выдвигается и проверяется гипотеза о равенстве коэффициента корреляции нулю. При проверке этой гипотезы используется t-статистика. Если гипотеза подтверждается, t-статистика имеет распределение Стьюдента. Если расчетное значение t р > t кр, то гипотеза отвергается, что свидетельствует о значимости линейного коэффициента корреляции, а следовательно, и о статистической существенности зависимости между Х и Y;
- Определяется интервальная оценка для статистически значимого линейного коэффициента корреляции.
- Определяется интервальная оценка для линейного коэффициента корреляции на основе обратного z-преобразования Фишера;
- Рассчитывается стандартная ошибка линейного коэффициента корреляции.
Результаты решения данной задачи с применяемыми функциями в пакете Excel приведены на рисунке 1.
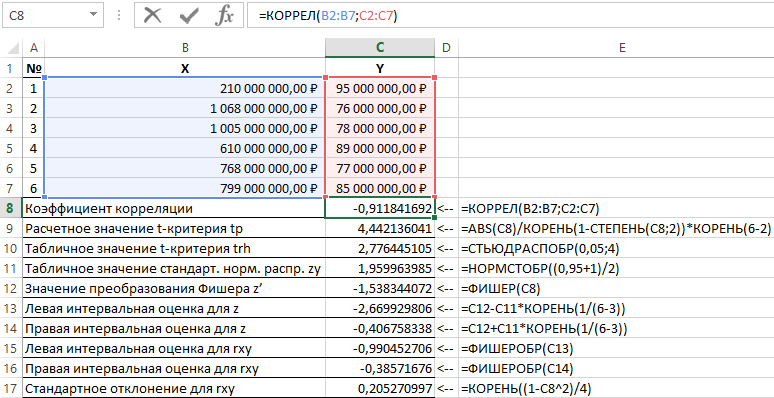
Рисунок 1 – Пример расчетов.
| № п/п | Наименование показателя | Формула расчета |
| 1 | Коэффициент корреляции | =КОРРЕЛ(B2:B7;C2:C7) |
| 2 | Расчетное значение t-критерия tp | =ABS(C8)/КОРЕНЬ(1-СТЕПЕНЬ(C8;2))*КОРЕНЬ(6-2) |
| 3 | Табличное значение t-критерия trh | =СТЬЮДРАСПОБР(0,05;4) |
| 4 | Табличное значение стандартного нормального распределения zy | =НОРМСТОБР((0,95+1)/2) |
| 5 | Значение преобразования Фишера z’ | =ФИШЕР(C8) |
| 6 | Левая интервальная оценка для z | =C12-C11*КОРЕНЬ(1/(6-3)) |
| 7 | Правая интервальная оценка для z | =C12+C11*КОРЕНЬ(1/(6-3)) |
| 8 | Левая интервальная оценка для rxy | =ФИШЕРОБР(C13) |
| 9 | Правая интервальная оценка для rxy | =ФИШЕРОБР(C14) |
| 10 | Стандартное отклонение для rxy | =КОРЕНЬ((1-C8^2)/4) |
Таким образом, с вероятностью 0,95 линейный коэффициент корреляции заключен в интервале от (–0,386) до (–0,990) со стандартной ошибкой 0,205.
Проверка статистической значимости регрессии по функции FРАСПОБР
Пример 2. Произвести проверку статистической значимости уравнения множественной регрессии с помощью F-критерия Фишера, сделать выводы.
Для проверки значимости уравнения в целом выдвинем гипотезу Н 0 о статистической незначимости коэффициента детерминации и противоположную ей гипотезу Н 1 о статистической значимости коэффициента детерминации:
Н 1: R 2 ≠ 0.
Проверим гипотезы с помощью F-критерия Фишера. Показатели приведены в таблице 2.
Таблица 2 – Исходные данные
Для этого используем в пакете Excel функцию:
FРАСПОБР (α;p;n-p-1)
- α – вероятность, связанная с данным распределением;
- p и n – числитель и знаменатель степеней свободы, соответственно.
Зная, что α = 0,05, p = 2 и n = 53, получаем следующее значение для F крит (см. рисунок 2).

Рисунок 2 – Пример расчетов.
Таким образом можно сказать, что F расч > F крит. В итоге принимается гипотеза Н 1 о статистической значимости коэффициента детерминации.
Расчет величины показателя корреляции в Excel
Пример 3. Используя данные 23 предприятий о: X - цена на товар А, тыс. руб.; Y - прибыль торгового предприятия, млн. руб, производится изучение их зависимости. Оценка регрессионной модели дала следующее: ∑(yi-yx) 2 = 50000; ∑(yi-yср) 2 = 130000. Какой показатель корреляции можно определить по этим данным? Рассчитайте величину показателя корреляции и, используя критерий Фишера, сделайте вывод о качестве модели регрессии.
Определим F крит из выражения:
F расч = R 2 /23*(1-R 2)
где R – коэффициент детерминации, равный 0,67.
Таким образом, расчетное значение F расч = 46.
Для определения F крит используем распределение Фишера (см. рисунок 3).

Рисунок 3 – Пример расчетов.
Таким образом, полученная оценка уравнения регрессии надежна.
Для сравнения двух нормально распределенных совокупностей, у которых нет различий в средних выборочных значениях, но есть разница в дисперсиях, используют критерий Фишера . Фактический критерий рассчитывают по формуле:
где в числителе
стоит большее значение выборочной
дисперсии, а в знаменателе - меньшее.
Для вывода о достоверности различий
между выборками используют ОСНОВНОЙ
ПРИНЦИП
проверки статистических гипотез.
Критические точки для
 содержатся в таблице. Нулевую гипотезу
отвергают, если фактически установленная
величина
содержатся в таблице. Нулевую гипотезу
отвергают, если фактически установленная
величина превзойдет или окажется равной
критическому (стандартному) значению
превзойдет или окажется равной
критическому (стандартному) значению этой величины для принятого уровня
значимости
и числа
степеней свободы k
1
=
n
большая
-1
;
k
2
=
n
меньшая
-1
.
этой величины для принятого уровня
значимости
и числа
степеней свободы k
1
=
n
большая
-1
;
k
2
=
n
меньшая
-1
.
П р и м е р: при
изучении влияния некоторого препарата
на скорость проростания семян было
установлено, что в экспериментальной
партии семян и контроле средняя скорость
проростания одинакова, но есть разница
в дисперсиях. =1250,
=1250, =417.
Объемы выборок одинаковы и равны 20.
=417.
Объемы выборок одинаковы и равны 20.

 =2,12.
Следовательно, нулевая гипотеза
отвергается.
=2,12.
Следовательно, нулевая гипотеза
отвергается.
Корреляционная зависимость. Коэффициент корреляции и его свойства. Уравнения регрессии.
ЗАДАЧА корреляционного анализа сводится к:
Установлению направления и формы связи между признаками;
Измерению ее тесноты.
Функциональной называется однозначная зависимость между переменными величинами, когда определенному значению одной (независимой) переменнойх , называемой аргументом, соответствует определенное значение другой (зависимой) переменнойу , называемой функцией. (Пример : зависимость скорости химической реакции от температуры; зависимость силы притяжения от масс притягивающихся тел и расстояния между ними).
Корреляционной называется зависимость между переменными, имеющими статистистический характер, когда определенному значению одного признака (рассматриваемого в качестве независимой переменной) соответствует целый ряд числовых значений другого признака. (Пример : связь между урожаем и количеством осадков; между ростом и весом и т.д.).
Поле корреляции представляет собой множество точек, координаты которых равны полученным на опыте парам значений переменныхх иу .
По виду корреляционного поля можно судить о наличии или отсутствии связи и ее типе.



Связь называется положительной , если при увеличении одной переменной увеличивается другая переменная.
Связь называется отрицательной , если при увеличении одной переменной уменьшается другая переменная.
Связь называется
линейной
, если ее можно в
аналитическом виде представить как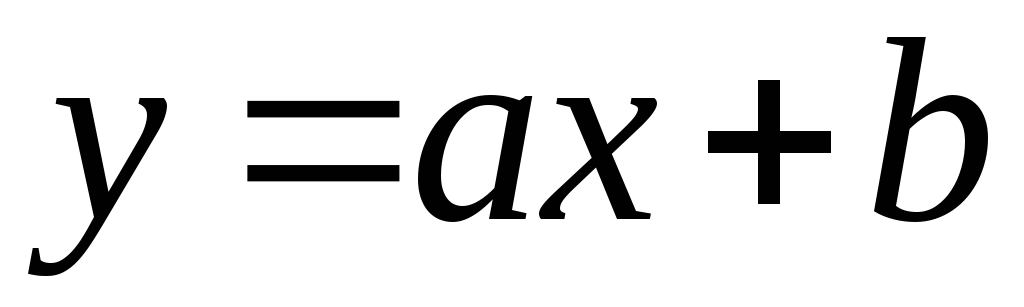 .
.
Показателем тесноты связи является коэффициент корреляции . Эмпирический коэффициент корреляции определяется выражением:

Коэффициент корреляции лежит в пределах от -1 до1 и характеризует степень близости между величинамиx иy . Если:

Корреляционную
зависимость между признаками можно
описывать разными способами. В частности,
любая форма связи может быть выражена
уравнением общего вида
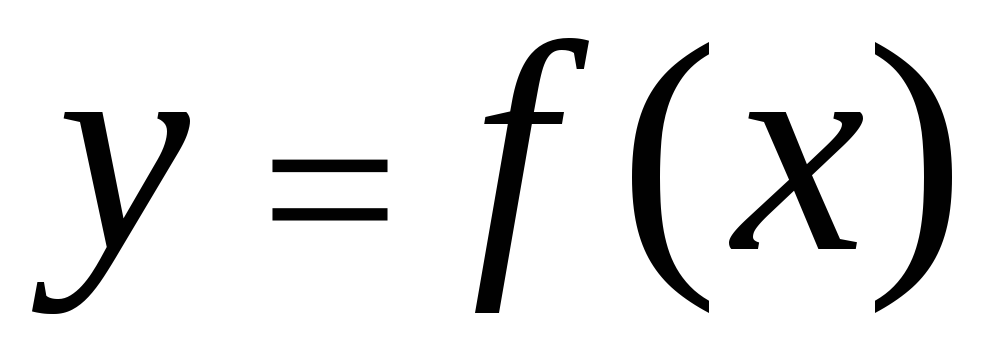 .
Уравнение вида
.
Уравнение вида и
и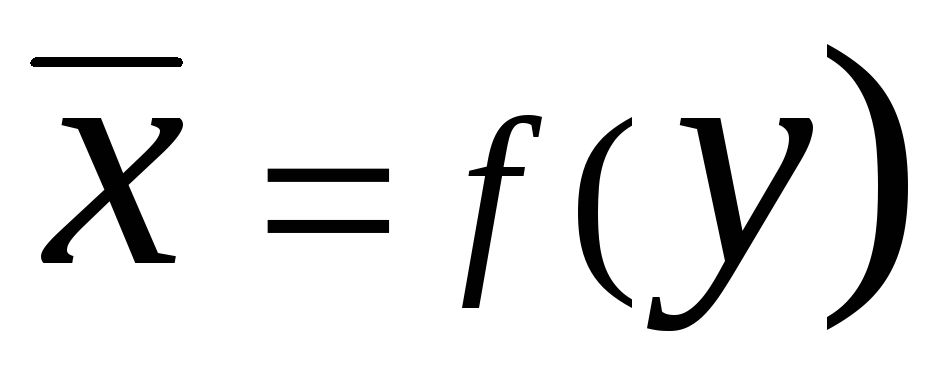 называютсярегрессией
. Уравнение
прямой регрессииу
нах
в общем случае можно записать в виде
называютсярегрессией
. Уравнение
прямой регрессииу
нах
в общем случае можно записать в виде

Уравнение прямой регрессии х нау в общем случае выглядит как

Наиболее вероятные значения коэффициентов а и в , с и d могут быть вычислены, например, при использовании метода наименьших квадратов.
Критерий Фишера позволяет сравнивать величины выборочных дисперсий двух независимых выборок. Для вычисления F эмп нужно найти отношение дисперсий двух выборок, причем так, чтобы большая по величине дисперсия находилась бы в числителе, а меньшая – в знаменателе. Формула вычисления критерия Фишера такова:
где - дисперсии первой и второй выборки соответственно.
Так как, согласно условию критерия, величина числителя должна быть больше или равна величине знаменателя, то значение F эмп всегда будет больше или равно единице.
Число степеней свободы определяется также просто:
k 1 =n l - 1 для первой выборки (т.е. для той выборки, величина дисперсии которой больше) и k 2 = n 2 - 1 для второй выборки.
В Приложении 1 критические значения критерия Фишера находятся по величинам k 1 (верхняя строчка таблицы) и k 2 (левый столбец таблицы).
Если t эмп >t крит, то нулевая гипотеза принимается, в противном случае принимается альтернативная.
Пример 3. В двух третьих классах проводилось тестирование умственного развития по тесту ТУРМШ десяти учащихся. Полученные значения величин средних достоверно не различались, однако психолога интересует вопрос - есть ли различия в степени однородности показателей умственного развития между классами.
Решение. Для критерия Фишера необходимо сравнить дисперсии тестовых оценок в обоих классах. Результаты тестирования представлены в таблице:
Таблица 3.
|
№№ учащихся |
Первый класс |
Второй класс |
Рассчитав дисперсии для переменных X и Y, получаем:
s x 2 =572,83; s y 2 =174,04
Тогда по формуле (8) для расчета по F критерию Фишера находим:
![]()
По таблице из Приложения 1 для F критерия при степенях свободы в обоих случаях равных k=10 - 1 = 9 находим F крит =3,18 (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н 0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н 1 . Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
6.2 Непараметрические критерии
Сравнивая на глазок (по процентным соотношениям) результаты до и после какого-либо воздействия, исследователь приходит к заключению, что если наблюдаются различия, то имеет место различие в сравниваемых выборках. Подобный подход категорически неприемлем, так как для процентов нельзя определить уровень достоверности в различиях. Проценты, взятые сами по себе, не дают возможности делать статистически достоверные выводы. Чтобы доказать эффективность какого-либо воздействия, необходимо выявить статистически значимую тенденцию в смещении (сдвиге) показателей. Для решения подобных задач исследователь может использовать ряд критериев различия. Ниже будет рассмотрены непараметрические критерии: критерий знаков и критерий хи-квадрат.
На данном примере рассмотрим, как оценивается надежность полученного уравнение регрессии. Этот же тест используется для проверки гипотезы о том, что коэффициенты регрессии одновременно равны нулю, a=0 , b=0 . Другими словами, суть расчетов - ответить на вопрос: можно ли его использовать для дальнейшего анализа и прогнозов?
Для установления сходства или различия дисперсий в двух выборках используйте данный t-критерий .
Итак, целью анализа является получение некоторой оценки, с помощью которой можно было бы утверждать, что при некотором уровне α полученное уравнение регрессии - статистически надежно. Для этого используется коэффициент детерминации R 2
.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k 1 =(m) и k 2 =(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H 0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
![]()
![]()
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2 (или через функцию Excel FРАСПОБР(вероятность;1;n-2)).
F табл - это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости α. Уровень значимости α - вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно α принимается равной 0,05 или 0,01.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k 1 =1 и k 2 =48, F табл = 4
Выводы : Поскольку фактическое значение F > F табл, то коэффициент детерминации статистически значим (найденная оценка уравнения регрессии статистически надежна ) .
Дисперсионный анализ
.Показатели качества уравнения регрессии
Пример
. По совокупности 25 предприятий торговли изучается зависимость между признаками: X - цена на товар А, тыс. руб.; Y - прибыль торгового предприятия, млн. руб. При оценке регрессионной модели были получены следующие промежуточные результаты: ∑(y i -y x) 2 = 46000; ∑(y i -y ср) 2 = 138000. Какой показатель корреляции можно определить по этим данным? Рассчитайте величину этого показателя, на основе этого результата и с помощью F-критерия Фишера
сделайте вывод о качестве модели регрессии.
Решение. По этим данным можно определить эмпирическое корреляционное отношение :  , где ∑(y ср -y x) 2 = ∑(y i -y ср) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92 000.
, где ∑(y ср -y x) 2 = ∑(y i -y ср) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92 000.
η 2 = 92 000/138000 = 0.67, η = 0.816 (0.7 < η < 0.9 - связь между X и Y высокая).
F-критерий Фишера
: n = 25, m = 1.
R 2 = 1 - 46000/138000 = 0.67, F = 0.67/(1-0.67)x(25 - 1 - 1) = 46. F табл (1; 23) = 4.27
Поскольку фактическое значение F > Fтабл, то найденная оценка уравнения регрессии статистически надежна.
Вопрос: Какую статистику используют для проверки значимости модели регрессии?
Ответ: Для значимости всей модели в целом используют F-статистику (критерий Фишера).







