
- Суть и виды статистических группировок.
- Выполнение группировки по количественному признаку.
- Ряды распределения, их виды и графическое изображение.
Суть и виды статистических группировок
В результате первой стадии статистических исследований (статистического наблюдения) получают статистическую информацию , представляющую собой большое количество первичных, разрозненных сведений об отдельных единицах объекта исследования (например, записи о каждом гражданине страны при переписи населения: пол, национальность, возраст, образование и др.).
Дальнейшая задача статистики заключается в этом, чтобы привести эти материалы в определенный порядок, систематизировать и на этой основе дать сводную характеристику всей совокупности фактов для того, чтобы изучить характерные черты и отличительные особенности изучаемого явления и выявить закономерности его развития. Это достигается на второй стадии статистического исследования, первой ступенью которой является статистическая сводка.
Статистическая сводка – это научно организованная обработка первичных данных в целях получения обобщающих характеристик изучаемого явления по ряду существенных для него признаков.
Если производится только подсчет общих итогов по изучаемой совокупности единиц наблюдения, то сводка называется простой. Например: чтобы узнать общую численность студентов высших учебных заведений Украины достаточно сложить количество студентов всех ВУЗов на определенную дату.
Статистическая сводка включает в себя такие составляющие элементы:
- выбор группировочных признаков (например, после переписи население можно делить на группы по признакам: пол, возраст, национальность);
- распределение данных на части (группы и подгруппы);
- расчет итоговых групповых данных с помощью системы статистических показателей.
- систематизация полученных результатов в виде статистических таблиц.
Объединение отдельных единиц статистической совокупности в группы осуществляется при помощи метода группировок.
Статистическая группировка – это процесс образования однородных групп по ряду существенных признаков. Осуществляется группировка либо путем деления совокупности на отдельные части, которые характеризуются внутренней однородностью и отличаются рядом признаков, либо путем объединения отдельных единиц в группы по типовым признакам (например, группировка промышленных предприятий по форме собственности, группировка населения по размеру среднедушевого дохода, группировка коммерческих банков по сумме актива баланса и т.д.).
Признаки, по которым производится распределение единиц изучаемой совокупности на группы, называются группировочными признаками
или основанием группировки
. Если группировка получена по количественному признаку, она называется количественной, по качественному – атрибутивной или качественной.
На группировку в статистическом анализе возлагаются следующие функции:
- выделение социально-экономических типов явлений;
- изучение структуры и структурных сдвигов;
- анализ взаимосвязей между явлениями.
В соответствии с этими функциями различают типологические, структурные и аналитические (факторные) группировки.
Типологическая
группировка – это распределение качественно разнородной
совокупности на классы, социально-экономические однородные типы. К этому виду относятся группировки стран по социально-политическому устройству, предприятий – по форме собственности, населения – по месту проживания (городское и сельское).
Разделение однородной
совокупности на группы с целью выявления ее внутренней структуры называется структурной
группировкой. Она характеризует состав совокупности, объем (весомость) ее отдельных групп.
Таблица 1 – Группировка потребителей йогурта по возрасту
Анализ структурных группировок, взятых за ряд периодов или моментов времени, показывает изменение структуры изучаемых явлений, т.е. структурные сдвиги , что отражает закономерности их развития.
Аналитические группировки
используются для исследования наличия зависимости между изучаемыми явлениями. Для этого следует данные сгруппировать по одному из признаков, вычислить в каждой группе среднее значение второго признака, а затем сопоставить изменения изучаемых признаков. Если с увеличением или уменьшением группировочного признака увеличиваются значения второго признака, то связь (прямая или обратная) между ними существует.
Таблица 2 – Группировка магазинов по численности работников (данные условные)
Численность работников, чел. |
Количество магазинов |
Средняя фактическая продолжительность рабочей недели, ч. |
100 и более |
Данные показывают, что между размером предприятия и занятостью его работников существует связь: чем больше по количеству работающих магазин, тем короче рабочая неделя.
Если группы, образованные по одному признаку, делятся затем на группы по второму и т.д. признакам, то такая группировка называется комбинированной
. Например, распределив группы потребителей йогурта по полу, получим комбинированную группировку.
Таблица 3 – Группировка потребителей йогурта по возрасту и полу
Группы потребителей по возрасту, лет |
Число потребителей, чел. |
||||
мужского пола |
женского пола |
||||
Менее 20 |
10 |
4 |
6 |
||
Выполнение группировки по количественному признаку
При составлении структурных группировок на основе количественных признаков определяют количество групп и интервалы группировки .
Интервал
– количественное значение, определяющее и отделяющее одну группу от другой, т.е. он очерчивает количественные границы групп.
Интервалы могут быть равные и неравные. Например: по численности работающих предприятия могут быть разбиты на группы: до 100, 100-200, 200-500, 500-1000, 1000 и более. Это объясняется тем, что изменение признака на 50-100 чел. имеет существенное значение для мелких предприятий, а для крупных – не имеет.
Для группировок с равными интервалами величина (длина, шаг) интервала определяется по формуле:
,
где ,– наибольшее и наименьшее значение признака;
к – число групп (интервалов), определяемое по формуле Стерджесса:
![]() ,
,
где N – число единиц совокупности.
Округление полученных в расчетах нецелых чисел производится в большую сторону.
Например: необходимо произвести группировку с равными интервалами 20 рабочих цеха по производительности их труда. Наибольшая производительность 180 деталей за смену, наименьшая – 60.
Количество групп:
Длина интервала: ![]() дет.
дет.
Нижняя граница 1-ой группы 60 деталей, верхняя 60+20=80 деталей. Вторая группа: нижняя граница 80, верхняя 80+20=100 и т.д. В результате получаем такой интервальный ряд (или такие группы рабочих), деталей:
1 группа: 60-80
2 группа: 80-100
3 группа: 100-120
4 группа: 120-140
5 группа: 140-160
6 группа: 160-180
В этом распределении имеется неопределенность, к какой группе отнести единицу совокупности, значение признака которой равно граничному значению интервала (рабочих с производительностью 80, 100, 200 и т. д. дет/см). Для устранения неопределенности используют принцип единообразия: левая, нижняя граница интервала включает в себя указанное значение, а верхняя – нет. Значит, рабочего, производящего 100 дет/см, относят к 3 группе.
Интервалы групп могут быть закрытыми , когда указаны верхняя и нижняя границы (как в примере), и открытыми , когда указана лишь одна из границ. Например, интервалы «менее 60» или «180 и выше» - открытые интервалы. Для расчета показателей статистической совокупности открытые интервалы необходимо «закрыть». Для этого используют величину интервала, соседнего с «открытым». В примере получим: 40-60 и 180-200.
Сказанное выше относится к группировкам, которые производятся на основе анализа первичного статистического материала. Но довольно часто приходится пользоваться уже имеющимися группировками, которые не удовлетворяют требованиям анализа. Например, группировки могут быть не сопоставимы из-за различного числа групп или неодинаковых границ интервалов. Для приведения группировок к сопоставимому виду используется метод вторичной группировки
, который заключается в образовании новых групп на основе ранее осуществленной группировки. Эта перегруппировка возможна двумя способами: 1) объединением первоначальных интервалов (т.е. их укрупнением); 2) долевой перегруппировкой.
Рассмотрим пример, данные условные.
Таблица 3 – Группировка акционеров по размеру дивидендов на одну акцию.
1-й район |
|||||
№ груп-пы |
Количество акционеров, % |
№ груп-пы |
Группы акционеров по размеру диви-дендов, грн. |
Количество акционеров, % |
|
1 |
1 – 4 |
18 |
1 |
1– 6 |
10 |
Приведенные данные не позволяют сравнить распределение акционеров двух районов по размеру дивидендов из-за различного числа групп (5 и 4) и различной длины интервала. Взяв за основу группировку 2-го района (как более крупную), произведем вторичную группировку акционеров 1-го района.
Таблица 4 – Вторичная группировка акционеров по размеру дивидендов на 1 акцию
№ груп-пы |
Группы акционеров по размеру дивидендов, % |
Количество акционеров, % |
||
1 |
1 – 6 |
10 |
24 |
18+0,5*12=24 |
Анализ сопоставимых данных вторичной группировки позволяет сделать вывод: акционеры второго района имеют более высокие дивиденды: (12 и выше грн. получают 40+30=70 % акционеров, а в первой – только 30 %).
Ряды распределения, их виды и графическое изображение
Статистический ряд распределения – это упорядоченное распределение единиц изучаемой совокупности на группы по определенному варьирующему признаку (предыдущий пример – это ряд распределения). Он, являясь разновидностью структурной группировки, характеризует состав (или структуру) изучаемого явления, позволяет судить об однородности совокупности, закономерности распределения и границах варьирования единиц совокупности.
Ряды распределения, построенные по атрибутивному признаку, называются атрибутивными
(распределение населения по полу, занятости, профессии и т.д.).
Ряды, построенные по количественному признаку, - вариационными
(распределение населения по стажу работы, з/п, возрасту.).
Конструктивно вариационный ряд распределения представляет собой таблицу, в первом столбце которой расположены варианты или их интервалы, во второй – частоты или (и) частости (третий столбец) . Принято варианты обозначать, частоты - , частости - .
Варианты, т.е. числовые значения количественного признака в вариационном ряду распределения, могут быть положительными или отрицательными. Так, при группировке предприятий по результатам деятельности варианты положительные (прибыль) или отрицательные (убыток).
Частоты – это числа, показывающие, как часто встречаются те или варианты в данной совокупности. Сумма всех частот называется объемом совокупности и показывает число единиц совокупности, обозначается N.
Частости
–
это частоты, выраженные в виде относительных величин: долях единицы или в процентах, рассчитываются как отношение частоты к объему совокупности. Сумма частостей всегда равна единице или 100 %. Замена частот частостями позволяет сопоставлять вариационные ряды с разным числом наблюдений.
Для анализа совокупности вариационный ряд дополняют такими элементами, как накопленная частота, накопленная частость и плотность распределения.
Накопленная частота (Sf)показывает число единиц совокупности, у которых значение варианты не больше данной, определяется суммированием частот всех предшествующих интервалов, включая данный:
, ,![]() и т.д.
и т.д.
Если вместо частот использовать частости, то аналогично получим накопленные частости (Sw):
, , ![]() и т.д.
и т.д.
Абсолютная плотность распределения
– это частота, приходящаяся на единицу длины интервала, т. е. , а относительная плотность распределения
– частость, приходящаяся на единицу длины интервала, т. е. . Плотность распределения используется в рядах с неравными интервалами для приведения частот и частостей к сопоставимому виду.
Вариационные ряды в зависимости от характера вариации делят на дискретные
и интервальные.
Дискретные вариационные ряды строятся на основе дискретных (прерывных) признаков. Дискретные – это признаки, варианты которых имеют только целые значения и количество их невелико. Интервальные вариационные ряды основаны на непрерывных признаках (т.е. принимающих любые значения, в том числе и дробные) или дискретных, варьирующих в широком диапазоне.
Пример построения дискретного ряда распределения
. Стаж работы в годах 10 рабочих бригады характеризуются следующими данными: 5, 3, 5, 4, 3, 4, 5, 4, 2, 4.
Первым шагом в упорядочении первичного ряда является его ранжирование
, т.е. расположение всех вариант в возрастающем или убывающем порядке.
Ранжированный ряд: 2, 3, 3, 4, 4, 4, 4, 5, 5, 5.
Таблица 5 – Дискретный вариационный ряд распределения рабочих по стажу работы
Стаж работы (варианты хi) |
Количество рабочих определенного стажа (частота fi) |
Частости |
Накопленные частоты |
Накопленные частости |
2 |
1 |
(1:10)*100=10 |
1 |
10 |
Пример построения интервального ряда . Имеются данные о среднемесячной з/п 30 работников, которая варьируется от 600 до 1200 грн. Построить интервальный ряд распределения.
Таблица 6 – Интервальный вариационный ряд распределения рабочих по размеру среднемесячной заработной платы
Группы рабочих по размеру з/п (интервалы вариант хi) |
Количество рабочих (частоты fi) |
Частости |
Накопленные частоты |
Накопленные частости |
||
1) 600-700 |
3 |
|
3 |
10,0 |
||
Графически ряды распределения можно представить в виде гистограммы, кумуляты, полигона.
Интервальный вариационный ряд изображают в виде гистограммы
. Для ее построения в прямоугольной системе координат по оси абсцисс откладывают отрезки, равные длине интервала. Затем на этих отрезках, как на основаниях, строят прямоугольники, высота которых пропорциональна частоте или частости. Для интервального ряда с неравными интервалами по оси ординат откладывают плотность распределения, так как в этом случае именно она дает представление о заполненности интервала. Площадь всей гистограммы численно равна сумме частот.
Пример построения гистограммы.
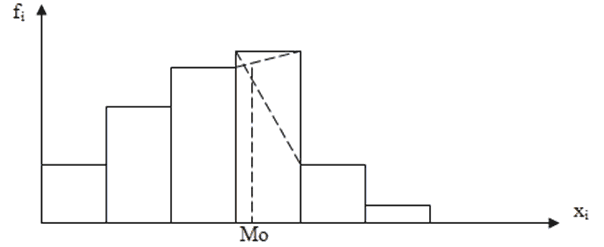
Если соединить середины каждого интервала отрезками прямой, то получим замкнутую фигуру в виде многоугольника, которая называется полигоном
.
Полигон чаще используется для дискретных рядов. Для этого в прямоугольной системе координат строят точки с координатами (x1, f1), (x2, f2), …, (xN, fN), затем последовательно соединяют их отрезками, а из первой и последней точек опускают перпендикуляры на ось х. Полученный многоугольник является полигоном дискретного вариационного ряда.
Кумулята строится по накопленным частотам (или частостям), которые откладывают по оси у, а по оси х – варианты или верхние границы интервалов.
Наряду с первичным группировкой в статистике находит широкое применение вторичное группировки. в Вторичным группировкой называют образование новых групп на основе ранее проведенной группировки.
Вторичное группировки используют для решения различных задач, важнейшими из которых являются: 1) образование на основе группировок по количественным признакам качественно однородных групп (типов); 2) приведение двух (или более) группировок с различными интервалами к единому виду с целью сопоставимости и анализа; 3) образование более укрупненных групп, в которых яснее проявляется характер распределения.
Суть этого приема заключается в получении сопоставимых данных по различным групуваннях, для чего: численный состав группы (с процентом) фиксируется на одном уровне у всех групуваннях; во всех групуваннях устанавливается также равное число групп и одинаковое содержание групповых таблиц. Сравнению и сопоставлению подлежат не абсолютные показатели по группам, а относительные величины, процентные отношения.
Различают два способа вторичной группировки: 1) путем преобразования интервалов первичного группирования (чаще простым укрупнением интервалов) и 2) путем закрепления за каждой группой определенной части единиц совокупности (частичная перегруппировка). При использовании этих способов вторичного группировки обычно предполагают, что распределение признака внутри интервалов будет равномерным.
Применение вторичного группировки для приведения двух группировок с различными интервалами к единому виду в целях сравнимости проиллюстрируем на следующем примере. Для этого используем данные первичного группирования двух районов по численности работников животноводства (табл. 3.7).
Таблица 3.7. Группировка хозяйств двух районов по численности работников животноводства
|
Район I |
Район II |
||
|
группы хозяйств по |
группы хозяйств по |
||
|
в итоге |
численностью работников, чел. |
в итоге |
|
Непосредственно данные группировок двух районов несопоставимы, так как хозяйства распределены по группам с разными интервалами: 20 чел. в районе I и 30 чел. в районе II. Число выделенных групп также неодинаковое.
Для приведения двух группировок в сопоставимый вид проведем вторичную группировку. С этой целью перегрупуємо материалы в группы, единые для обоих районов: возьмем интервал 40 чел. (табл. 3.8).
Поскольку есть возможность вторичное группировка хозяйств района И осуществить способом простого укрупнения интервалов (имеет место совпадение нижних и верхних интервалов в двух групуваннях), используем этот способ для решения поставленной задачи.
Поясним последовательность расчетов. В первую группу хозяйств с численностью работников до 160 чел. войдут хозяйства I и II групп.
Таблица 3.8. Вторичное группировка хозяйств двух районов по численности работников животноводства
Удельный вес хозяйств этих групп в общем итоге составит 16% (4+12). Во вторую группу хозяйств с численностью работников от 160 до 200 чел. войдут хозяйства III и IV групп их удельный вес в общем итоге составит 45% (18+27). Аналогично выполняются расчеты при образовании остальных групп.
Перегрупуємо хозяйства района II. Поскольку укрупнение интервалов для хозяйств района II не подходит и задачи не решает используем способ частичного перегруппировки данных первичного группирования.
В первую, заново созданную группу хозяйств района II с численностью работников животноводства до 160 чел., полностью войдут хозяйства первичного группирования с таким же интервалом. Удельный вес хозяйств этой группы составляет 8%.
Во вторую группу хозяйств вторичного группировки с численностью работников от 160 до 200 чел. полностью войдут хозяйства II группы (16%) и часть хозяйств III группы. Для определения части хозяйств, которую нужно взять из III группы, необходимо ее расчленить на подгруппы с численностью работников 190 - 200, 200 - 210, 210 - 220 чел. Показатели удельного веса хозяйств в этих подгруппах определяются пропорционально делению величины интервала. Величина интервала, которую мы рассматриваем, составляет 30 чел. и делится на три равные части. Для получения нужного интервала 160 - 200 чел. до величины интервала II группы (160 - 190 чел.) следует добавить одну треть величины интервала III группы (190 - 220 чел.) и такую же часть хозяйств этой группы.
Итак, в другую, вновь созданную группу хозяйств, войдут 16% хозяйств второй группы и одна треть III группы - 10% (1/3-30), что составит 26% общей численности хозяйств района II.
В III группу хозяйств вторичного группировки (200 - 240 чел.) войдет часть хозяйств III группы (190 - 220 чел.), что осталась, - 20% (%-30) и две трети хозяйств IV группы (220 - 250 чел.) - 14% (%-21), то есть 34% всей численности хозяйств района II.
Аналогичные расчеты выполняются и при образовании остальных, заново созданных групп хозяйств: 240 - 280 и более 280 чел. Как бы в табл. 3.7 наряду с данными о удельный вес хозяйств по группам были приведены данные об их численности, то расчеты во вновь созданных группах выполнялись бы в тех же соотношениях, что и по удельным весом хозяйств.
После вторичного группировки первичный материал становится сопоставимым, поскольку для двух районов взяты одинаковые группы по численности работников. Из данных табл. 3.8 видно, что распределение хозяйств по численности работников животноводства в двух районах существенно отличается: в районе I преобладают хозяйства с численностью работников животноводства до 200 чел. (61% общей численности хозяйств), в районе II - хозяйства с численностью работников животноводства - свыше 200 чел. (66% общей численности хозяйств).
Группировка данных производится в соответствии с программой сводки для того, чтобы впоследствии представить полученную информацию доступно для восприятия.
Группировка — объединение единиц совокупности в некоторые группы, имеющие свои характерные особенности, общие черты и сходные размеры изучаемого признака.
Результаты группировки оформляются в виде группировочных таблиц , делающих информацию обозримой. Таблица содержит сводную числовую характеристику исследуемой совокупности по одному или нескольким существенным признакам, взаимосвязанным логикой анализа.
Пример 5.2. Основа группировочной таблицы
Название таблицы (общий заголовок)
Группировочная таблица содержит три вида заголовков: общий, верхний и боковые. Заголовки таблиц должны быть краткими и раскрывать содержание показателей.
Общий заголовок отражает содержание всей таблицы с указанием, к какому месту и времени она относится. Он располагается над макетом по центру и является внешним заголовком. Верхние заголовки характеризуют содержание граф (заголовки сказуемого), а боковые (заголовки подлежащего) — строк. Подлежащее статистической таблицы — объект, характеризующийся цифрами. Сказуемое — система показателей, которыми характеризуется объект изучения, т.е. подлежащее. Следует избегать появления клеток, в которых не может быть исходных данных. В клетках, где отсутствуют данные по причине неполноты исходной информации, делают специальные пометки.
Пример 5.3. Пример группировочной таблицы
Отношение студентов факультета ГиСЭО к понижению размера стипендии (по результатам исследования в январе 1999 г.)
Таким образом, группировка — это разделение единиц совокупности на группы по выбранным варьирующим признакам.
Группировки различают по:
Задачам систематизации данных;
Числу группировочных признаков;
Используемой информации.
По задачам систематизации данных различают: типологические, структурные и аналитические.
Типологические группировки предназначены для выявления качественно однородных групп совокупностей, т.е. объектов, близких друг к другу одновременно по всем группировочным признакам. Например, группировка предприятий города по формам собственности. Типологическая группировка разбивает разнородную совокупность единиц наблюдения на качественно однородные группы (классы, типы явлений). При ее построении в качестве группировочных признаков могут использоваться количественные и атрибутивные признаки.
Структурные группировки— это разделение однородной совокупности на группы, характеризующие ее структуру по определенному группировочному признаку. Например, группировка рабочих цеха по квалификации. Другим примером структурной группировки является группировка отраслей экономики в топливно-энергетическую, нефтехимию, аграрно-промышленный комплекс, горнодобывающую, телекоммуникационную, транспортную, металлургию, оборонные отрасли и т.п. По своей природе структурная группировка является также достаточно общей, хотя в отдельных случаях по общности она и уступает типологическим группировкам.
Аналитические группировки предназначены для выявления зависимости между признаками. Строят аналитические группировки, выделив результирующие признаки, т.е. признаки, которые изменяются под влиянием факторных признаков, и факторные признаки, т.е. те, зависимость результирующих признаков от которых исследуется. Аналитическая группировка отличается следующими особенностями: единицы совокупности группируются по факторному признаку; каждая выделенная группа характеризуется средними значениями результативного признака, по изменению величины которых определяется наличие связи и зависимостей между признаками. Каждая выделенная группа должна содержать статистически однородные единицы совокупности по группировочному признаку. Количество единиц в каждой выделенной группе должно быть достаточным для получения надежных статистических характеристик исследуемого явления или процесса.
По используемой информации различают первичные и вторичные группировки.
Первичные группировки производятся на основе исходных данных, полученных в результате статистических наблюдений.
Вторичные группировки — результат объединения или расщепления первичных группировок, они позволяют преодолевать несопоставимость исходных данных в первичных группировках и тем самым объединять их в одну общую и выполнять сравнение, сопоставление данных, представленных в них после проведения вторичной группировки.
При разработке первичной группировки существенное значение имеет выбор числа групп . Число групп зависит от типа признака, положенного в основу группировки (основания группировки), от объема совокупности, степени вариации признака.
При построении группировок по качественному признаку количество групп соответствует количеству уровней градации признака. При группировании по количественному признаку все множество значений признака делится на интервалы. При этом возможно два подхода: группировка с равными и неравными интервалами.
Для определения этих параметров в первом случае рекомендуется формула Стерджесса:
n = 1 + (3,322× lgN) , (5.1)
где N — количество наблюдений.
В этом случае величина интервала:
I = (Хmax - Xmin)/n . (5.2)
Основные этапы построения статистических группировок включают:
Выбор группировочного признака;
Определение необходимого числа групп, на которые следует разбить изучаемую совокупность;
Установление границ интервалов группировки;
Установление для каждой группировки показателей или их системы, которыми должны характеризоваться выделенные группы.
Группировка с неравными интервалами порождает массу проблем при обработке данных, поэтому следует, по мере возможности, избегать таких группировок.
Вопросы для самопроверки:
Что такое сводка?
Что представляет собой группировка данных?
Какие вы знаете виды группировок?
В чем особенности каждого вида группировки?
Какова связь между группировкой, таблицей и сводкой?
В чем особенность сложных многомерных группировок?
Что означает вторичная группировка?
Для чего нужна вторичная группировка?
При анализе и сопоставлении нескольких группировок, например по нескольким цехам, предприятиям и т.д., может возникнуть ситуация когда исходные группировки несопоставимы из-за различного числа групп или разной величины используемых интервалов. Чтобы такие группировки привести в сопоставимый вид, т.е. либо к одному числу групп, либо к одной величине интервала, используется метод вторичной группировки. Метод вторичной группировки – это метод образования новых групп на основании имеющихся по заданным требованиям группировки. Для проведения вторичной группировки используются 2 способа: 1) объединение первоначальных групп, 2) долевая перегруппировка.
Приведение нескольких несопоставимых группировок в сопоставимой вид осуществляется в три этапа. На первом этапе осуществляется анализ исходных группировок на предмет выявления условий несопоставимости исходных группировок. На втором этапе выбирается способ приведения исходных группировок в сопоставимый вид. На третьем этапе осуществляется вторичная перегруппировка исходных группировок и анализ полученных результатов. При необходимости осуществляется повторная перегруппировка. Рассмотрим способы вторичной перегруппировки.
1 способ Статистическое наблюдение о распределении рабочих предприятия по стажу работы в 2000 году дало следующие результаты (табл.2.7).
Таблица 2.7
В 2002 году была проведено повторное статистическое наблюдение, которое дало следующие результаты (табл.2.8). Оценить изменения в распределении рабочих по стажу за 2 года непосредственно по данным обеих таблиц невозможно. Анализ обеих таблиц показывает, что они несовместны из-за разного числа групп и разной величины интервала.
Таблица 2.8
Чтобы привести данные обеих таблиц к сопоставимому виду можно в таблице 2.7 объединить как 1 и 2 группы, так и 3 и 4 группы. Это даст возможность оценить изменения в распределении рабочих по стажу, которые произошли на предприятии за два года. Результаты перегруппировки данных статистического наблюдения за 2000год (табл.2.7) приведены в таблице 2.9.
Таблица 2.9
Сравнивая данные за 2002 год (табл.2.8) с перегруппированными данными за 2000 год (табл.2.9) можно сделать вывод: за два года уменьшилось число рабочих со стажем до 6 лет, т.е. молодых, и увеличилось число рабочих с большим стажем.
2 способ Пусть статистическое наблюдение в 2002 году дало такие результаты (табл.2.10). Сравнивая данные за 2000 год (табл.2.9) и данные за 2002 год (табл. 2.7) можно сделать вывод о их несовместности из-за разного числа групп и разной величины интервала. Анализ показывает, что применение 1 способа приведения данных к сопоставимому виду невозможно. Поэтому используем 2 способ для перегруппировки данных за 2000 год (табл.2.7) таким образом, чтобы они соответствовали группировке данных за 2002 год (табл.2.10)
Таблица 2.10
Применение второго способа предполагает равномерное распределение частот внутри каждой группы. Это является непременным условием использования второго способа. Для перегруппировки данных за 2000 год (табл.2.7)сделаем следующие расчеты. Так в новую первую группу (1-4) (табл.2.10) войдут все данные старой первой группы (1-3) (табл.22.7) и данные о количестве рабочих, имеющих стаж 4 года из старой второй группы. Число рабочих, имеющих стаж 4 года, равен 3 (9/3=3, так как в старой второй группе было 9 рабочих, а интервал равен 3). Таким образом, новая первая группа (1-4) будет включать 18 рабочих (18=15+3)Вторая новая группа (5-8) будет включать 6 рабочих, имеющих стаж 5, 6 лет (из старой второй группы 6=9/3·2) и 18 рабочих, имеющих стаж 7, 8 лет (из старой третьей группы 18=27/3·2) Таким образом, новая вторая группа (5-8) будет включать 24 рабочих (24=6+18). В новую третью группу (9-12) войдут рабочие, имеющие стаж 9 лет (9=27/3) и все 9 рабочих из старой четвертой группы (10-12). Таким образом, в новой третьей группе (9-12) будет 18 рабочих (18=9+9). Перегруппированные данные за 2000год и данные за 2002 год сведем в одну таблицу(2.11), что позволит осуществить сравнительный анализ.
Таблица 2.11
Анализ распределения рабочих предприятия по стажу (табл.2.11) показывает, что в 2002 году число рабочих с большим стажем (от 9 до 12 лет) увеличилось, а с меньшим стажем (от 1 до 8 лет) – уменьшилось. Таким образом, перегруппировка данных позволила привести данные в сопоставимый вид, провести анализ и сделать необходимые выводы.
Контрольные вопросы и задания
1.Что такое статистическое наблюдение? Какие условия должны быть реализованы при проведении статистического наблюдения (смотрите определение)?
2. По каким признакам можно классифицировать статистические наблюдения? Приведите примеры статистического наблюдения.
3. Какие ошибки возникают при проведении статистических наблюдений и какие методы контроля могут быть использованы?
4. Определите в каком примере дана простая, а в каком сложная сводка. Пример 1. В понедельник в ткацком цехе работало 200 работниц. Пример 2. В понедельник в ткацком цехе на участке №1 работало 40 работниц, на участке №2 – 60 работниц, а всего работало 100 работниц.
5. Какие группировки используются при обработке статистической информации? Чем они разнятся между собой?
6. В отделе главного технолога работает 15 человек, а в отделе маркетинга и сбыта 10 человек. В каком случае коллективы отделов являются однородными совокупностями, а в каком случае –неоднородными совокупностями.
7. Ежедневная реализация ткани артикула А в магазине Ткани в октябре месяце характеризовалась следующими данными (в метрах): 4, 11, 8, 14, 10, 19, 12, 11, 3, 6, 21, 9, 9, 5, 10, 13, 15, 7, 10, 13, 16, 12, 8, 11, 14, 15, 17. Осуществить группировку данных, используя равные интервалы.
8. Перегруппировать результаты группировки данных из пункта 7 в следующие группы: (3-9), (9-15), 15-21).
Тема № 3 СТАТИСТИЧЕСКИЕ РЯДЫ РАСПРЕДЕЛЕНИЯ, ТАБЛИЦЫ, ГРАФИКА
3.1 Статистические ряды распределения – понятие, виды, формы представления
Одной из форм представления данных статистического наблюдения является статистический ряд распределения. Статистический ряд распределения – это упорядоченное расположение единиц совокупности на группы по группировочному признаку. С помощью статистических рядов распределения возможно изучение структуры и границ изменения совокупности, оценка однородности и определение закономерности развития единицсовокупности. По виду статистические ряды распределения подразделяются на атрибутивные, вариационные и временные ряды.
Атрибутивные и вариационные ряды состоят из двух элементов: варианты и частоты (частости или плотности). Варианта () – это конкретное значение признака, которое он принимает в ряду распределения. Частота () – это абсолютное число, показывающее, сколько раз (как часто) встречается в совокупности то или иное значение признака (варианта) или сколько единиц совокупности обладают тем или иным значением признака (вариантой). Частость () – это относительная величина, определяющая долю отдельных вариант в общем объеме совокупности (). Частость может быть выражена либо в долях, в этом случае объем совокупности равен единице (), либо в процентах, этом случае объем совокупности равен 100% (). В целом частость рассчитывается следующим образом
где - объем совокупности.
Плотность () - это относительная величина, показывающая, сколько единиц совокупности (в абсолютной или относительной форме) приходится на единицу длины интервала группы (). Плотность может быть абсолютной или относительной. Абсолюная плотность равна
Относительная плотность равна
При расчете относительной плотности используется частость, выраженная в долях.
Атрибутивный ряд – это ряд, построенный на основе качественного признака совокупности. Данные ряды строятся с помощью типологической группировки и могут быть выражены в виде таблицы. Например, распределение рабочих предприятия по тарифным разрядам (табл.3.1).
Таблица 3.1
В приведенном примере (табл.3.1) совокупностью являются все рабочие предприятия. Объем совокупности равен 250 человекам. Единицей совокупности является один рабочий. В качестве признака единицы совокупности выбран тарифный разряд. Признак имеет несколько конкретных значений – вариант (1 разряд, 2 разряд, 3 разряд, 4 разряд, 5 разряд). В таблице значения признака приведены в графе 2, значения частот в графе 3, значение частости в графе 4.
Вариационный ряд – это ряд, построенный на основе количественного признака совокупности. Данные ряды строятся, в основном, с помощью структурной группировки и могут быть выражены в виде таблицы. Вариационные ряды бывают двух типов: дискретные вариационный ряды и интервальные. Дискретный вариационный ряд – это ряд, в котором значения признака (варианты) представлены дискретными величинами . Интервальный вариационный ряд – это ряд, в котором значения признака выражены в виде интервалов . На основе данных о ежедневном обороте 34 индивидуальных предпринимателей, приведенных на стр. , построим вариационный интервальный ряд (табл.3.2)
Таблица 3.2
В графе 3 приведена частота – количество предпринимателей, однодневный оборот которых попадает в определенный интервал (гр.2). В графе 4 рассчитана частость в процентах по формуле 3.1. Так частость для первой группы (3,1 – 3,9) будет равна
Аналогичным образом рассчитывается частость и для других групп. В графе 5 приведена частость в долях. Она может быть получена либо путем расчета
либо путем преобразования процентов в доли . При расчетах данные в десятичной форме нужно показывать с точность до 3 знаков после запятой. Это повышает точность расчетов и получение соответствующих итоговых данных. Так сумма частостей в процентах должна быть равна 100%, а в долях – равна 1.
В графе 6 таблицы 3.2 приведены значения абсолютной плотности. Расчет выполнен по формуле 3.2. Так для первой группы абсолютная плотность будет равна
Если частота () взята из графы 3, то величина интервала () определена как разность между верхней границей (3,9) и нижней границей (3,1) интервала первой группы, т.о. . Аналогичным образом рассчитывается абсолютная плотность для других групп. После выполнения расчетов необходимо дать им экономическую интерпретацию. Так, например, абсолютная плотность первой группы говорит о том, что на каждую тысячу руб. оборота в первой группе приходится 5 предпринимателей.
В графе 7 таблицы 3.2 приведены значения относительной плотности. Расчет выполнен по формуле 3.3. Так для первой группы относительная плотность будет равна
Аналогичным образом рассчитываются относительная плотность и для других групп. Относительная плотность первой группы говорит о том, что доля предпринимателей, приходящих на каждую тысячу оборота в первой группе, равна 0,147.
В графе 2 табл.3.3 представлен оборот в виде интервалов, а в графе 3 представлен оборот в виде дискретных величин. Для первой группы дискретная величина рассчитана следующим образом
Аналогичным образом рассчитывается оборот в виде дискретной величины и для других групп.
Часто при анализе вариационных рядов возникает потребность в понимании изменения объема совокупности при изменении (в основном в порядке возрастания) значений признака. Для этого используются такие понятия как накопленные частоты или накопленные частости. Накопленные частоты ( ) – это сумма частот сначала ряда до определенного значения признака включительно. Накопленные частости – это сумма частостей от начала ряда до определенного значения признака включительно. Рассмотрим нахождение значений этих показателей по данным табл. 3.4 В графе 6 табл. 3.4 приведены накопленные частоты. В первой группе (гр.1) 4 предпринимателя (гр.4) имели оборот от 3,1 до 3,9 тыс. руб. (гр.2) или средний оборот 3,5 тыс. руб. (гр.3). Поскольку эта первая группа, постольку и накопленная частота т.е. количество предпринимателей будет равно 4 (гр.6). Во второй группе количество предпринимателей, имеющих оборот от 3,9 до 4,7 тыс. руб. или средний оборот в 4,3 тыс руб. равно 5 чел. Отсюда накопленная частота, т.е. количество предпринимателей, имеющих оборот от 3,1 до 4,7 тыс руб. или в среднем от и менее 4, 3 тыс. руб., будет равна 9=4+5. Для третьей группы накопленная частота будет равна 16=4+5+7 и т.д. Аналогичным образом рассчитывается и накопленная частость.
Вторичная группировка
Вторичная группировка - это образование новых групп на основе ранее произведенной группировки. Применяют два способа образования новых групп на основе ранее произведенной группировки.
Первый способ состоит в укрупнении первоначальных интервалов. Это наиболее простой и распространенный способ.
Второй способ принято называть методом долевой перегруппировки и состоит в том, что за каждой группой закрепляется определенная доля единиц совокупности. Рассмотрим два способа на примере.
Имеется группировка сотрудников двух управлений одного из московских банков по размеру месячной заработной платы (цифры условные).
Таблица 3.6
| Кредитное управление | Валютное управление | ||||
| № группы | Число работников, чел. | № группы | Размер зарплаты, руб. в мес. | Число работников, чел. | |
| 2000 - 2500 | 2000 - 3000 | ||||
| 2500 - 3000 | 3000 - 5000 | ||||
| 3000 - 4000 | 5000 - 7000 | ||||
| 4000 - 5000 | 7000 и более | ||||
| 5000 и более | - | - | |||
| Итого | Итого |
Приведенные данные не позволяют сравнить распределение работников по размеру месячной заработной платы, так как величины интервалов различны, в связи с этим крайне важно привести эти ряды распределения к сопоставимому виду.
Произведем вторичную группировку, образовав группы с новыми укрупненными интервалами.
Таблица 3.7
При вторичной группировке методом долевой перегруппировки устанавливаем новые интервалы распределения работников по размеру месячной заработной платы, при этом за каждым интервалов закрепляем определенную долю единиц совокупности. В нашем примере одну из группировок (по кредитному управлению) оставляем без изменений. А по валютному управлению производим перегруппировку следующим образом. В первой группе с интервалом от 2000 до 3000 руб. частота равна 2. Применительно к группировке по кредитному управлению данный интервал крайне важно разбить на два равных интервала: от 2000 до 2500 руб. и от 2500 до 3000 руб., при этом исходная частота делится поровну. Следующий интервал от 3000 до 5000 руб. соответственно нужно разделить на два равных интервала: от 3000 до 4000 руб. и от 4000 до 5000 руб., при этом исходная частота делится поровну (6:2 = 3). Последние две группы крайне важно объединить в одну с интервалом 5000 руб. и выше.
Таблица 3.8
| № группы | Размер зарплаты, руб. в мес. | Кредитное число управления работников | Валютное число управления работников | ||
| чел. | в % к итогу | чел. | в % к итогу | ||
| 2000 - 2500 | 8,33 | 3,33 | |||
| 2500 - 3000 | 16,67 | 3,33 | |||
| 3000 - 4000 | 25,00 | 10,00 | |||
| 4000 - 5000 | 33,33 | 10,00 | |||
| 5000 и выше | 16,67 | 73,34 | |||
| Итого | 100,00 | 100,00 |
Контрольные вопросы
(выберите правильный ответ)
1. Статистическая сводка включает в себя:
а) только подсчет итогов в данных;
б) группировку данных и подсчет итогов;
в) группировку данных, подсчет итогов и расчет обобщающих показателей.
2. Группировка, в которой изучается структура совокупности, принято называть:
а) типологической; б) структурной; в) аналитической.
3. Группировочный признак может быть:
а) количественный;
б) качественный;
в) и количественный, и качественный.
4. Величина интервала определяется:
а) верхней границей интервала;
б) нижней границей интервала;
в) разностью верхней и нижней границ.
5. Вариационный ряд распределения строится:
а) по качественному признаку;
б) по количественному признаку.
6. Частоты - это:
а) абсолютные числа;
б) относительные числа.
7. Частости - это:
а) абсолютные числа;
б) относительные числа.
8. В дискретном вариационном ряду значения признака выражены:
а) в виде чисел;
б) в виде интервалов.
9. Интервальный вариационный ряд графически изображается в виде:
а) полигона распределения;
б) гистограммы;
в) кумуляты.
10. Вторичная группировка осуществляется методом:
а) уменьшения интервалов;
б) укрупнения интервалов;
в) и уменьшения, и укрупнения интервалов;
г) долевой перегруппировки.







