
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом . В то же время не все так плохо. При увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной. Поэтому при работе с большими размерами выборок можно использовать формулу выше.
Язык знаков полезно перевести на язык слов. Получится, что дисперсия — это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, мы просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Разгадка заключается всего в трех словах.
Однако в чистом виде, как, например, средняя арифметическая, или индекс, дисперсия не используется. Это скорее вспомогательный и промежуточный показатель, который необходим для других видов статистического анализа. У нее даже единицы измерения нормальной нет. Судя по формуле, это квадрат единицы измерения исходных данных. Без бутылки, как говорится, не разберешься.
{module 111}
Дабы вернуть дисперсию в реальность, то есть использовать в более приземленных целей, из нее извлекают квадратный корень. Получается так называемое среднеквадратичное отклонение (СКО) . Встречаются названия «стандартное отклонение» или «сигма» (от названия греческой буквы). Формула стандартного отклонения имеет вид:
![]()
Для получения этого показателя по выборке используют формулу:

Как и с дисперсией, есть и немного другой вариант расчета . Но с ростом выборки разница исчезает.
Среднеквадратичное отклонение, очевидно, также характеризует меру рассеяния данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными, так как единицы измерения у них одинаковые (это явствует из формулы расчета). Но и этот показатель в чистом виде не очень информативен, так как в нем заложено слишком много промежуточных расчетов, которые сбивают с толку (отклонение, в квадрат, сумма, среднее, корень). Тем не менее, со среднеквадратичным отклонением уже можно работать непосредственно, потому что свойства данного показателя хорошо изучены и известны. К примеру, есть такое правило трех сигм , которое гласит, что у данных 997 значений из 1000 находятся в пределах ±3 сигмы от средней арифметической. Среднеквадратичное отклонение, как мера неопределенности, также участвует во многих статистических расчетах. С ее помощью устанавливают степень точности различных оценок и прогнозов. Если вариация очень большая, то стандартное отклонение тоже получится большим, следовательно, и прогноз будет неточным, что выразится, к примеру, в очень широких доверительных интервалах.
Коэффициент вариации
Среднее квадратическое отклонение дает абсолютную оценку меры разброса. Поэтому чтобы понять, насколько разброс велик относительно самих значений (т.е. независимо от их масштаба), требуется относительный показатель. Такой показатель называется коэффициентом вариации и рассчитывается по следующей формуле:
Коэффициент вариации измеряется в процентах (если умножить на 100%). По этому показателю можно сравнивать самых разных явлений независимо от их масштаба и единиц измерения. Данный факт и делает коэффициент вариации столь популярным.
В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. Мне здесь трудно что-то прокомментировать. Не знаю, кто и почему так определил, но это считается аксиомой.
Чувствую, что я увлекся сухой теорией и нужно привести что-то наглядное и образное. С другой стороны все показатели вариации описывают примерно одно и то же, только рассчитываются по-разному. Поэтому разнообразием примеров блеснуть трудно, Отличаться могут лишь значения показателей, но не их суть. Вот и сравним, как отличаются значения различных показателей вариации для одной и той же совокупности данных. Возьмем пример с расчетом среднего линейного отклонения (из ). Вот исходные данные:

И график для напоминания.

По этим данным рассчитаем различные показатели вариации.
Среднее значение – это обычная средняя арифметическая.
Размах вариации – разница между максимумом и минимумом:
Среднее линейное отклонение считается по формуле:
Стандартное отклонение:
Расчет сведем в табличку.

Как видно, среднее линейное и среднеквадратичное отклонение дают похожие значения степени вариации данных. Дисперсия – это сигма в квадрате, поэтому она всегда будет относительно большим числом, что, собственно, ни о чем не говорит. Размах вариации – это разница между крайними значениями и может говорить о многом.
Подведем некоторые итоги.
Вариация показателя отражает изменчивость процесса или явления. Ее степень может измеряться с помощью нескольких показателей.
1. Размах вариации – разница между максимумом и минимумом. Отражает диапазон возможных значений.
2. Среднее линейное отклонение – отражает среднее из абсолютных (по модулю) отклонений всех значений анализируемой совокупности от их средней величины.
3. Дисперсия – средний квадрат отклонений.
4. Среднеквадратичное отклонение – корень из дисперсии (среднего квадрата отклонений).
5. Коэффициент вариации – наиболее универсальный показатель, отражающий степень разброса значений независимо от их масштаба и единиц измерения. Коэффициент вариации измеряется в процентах и может быть использован для сравнения вариации различных процессов и явлений.
Таким образом, в статистическом анализе существует система показателей, отражающих однородность явлений и устойчивость процессов. Часто показатели вариации не имеют самостоятельного смысла и используются для дальнейшего анализа данных (расчет доверительных интервалов
Квадратный корень из дисперсии носит название среднего квадратического отклонения от средней, которое рассчитывается следующим образом:
Элементарное алгебраическое преобразование формулы среднего квадратического отклонения приводит ее к следующему виду:
Эта формула часто оказывается более удобной в практике расчетов.
Среднее квадратическое отклонение так же, как и среднее линейное отклонение, показывает, на сколько в среднем отклоняются конкретные значения признака от среднего их значения. Среднее квадратическое отклонение всегда больше среднего линейного отклонения. Между ними имеется такое соотношение:
Зная это соотношение, можно по известному показатели определить неизвестный, например, но (I рассчитать а и наоборот. Среднее квадратическое отклонение измеряет абсолютный размер колеблемости признака и выражается в тех же единицах измерения, что и значения признака (рублях, тоннах, годах и т.д.). Оно является абсолютной мерой вариации.
Для альтернативных признаков, например наличия или отсутствия высшего образования, страховки, формулы дисперсии и среднего квадратического отклонения такие:
Покажем расчет среднего квадратического отклонения по данным дискретного ряда, характеризующего распределение студентов одного из факультетов вуза по возрасту (табл. 6.2).
Таблица 6.2.

Результаты вспомогательных расчетов даны в графах 2-5 табл. 6.2.
Средний возраст студента, лет, определен по формуле средней арифметической взвешенной (графа 2):
![]()
Квадраты отклонения индивидуального возраста студента от среднего содержатся в графах 3-4, а произведения квадратов отклонений на соответствующие частоты - в графе 5.
Дисперсию возраста студентов, лет, найдем по формуле (6.2):
![]()
Тогда о = л/3,43 1,85 *ода, т.е. каждое конкретное значение возраста студента отклоняется от среднего значения на 1,85 года.
Коэффициент вариации
По своему абсолютному значению среднее квадратическое отклонение зависит не только от степени вариации признака, но и от абсолютных уровней вариантов и средней. Поэтому сравнивать средние квадратические отклонения вариационных рядов с различными средними уровнями непосредственно нельзя. Чтобы иметь возможность для такого сравнения, нужно найти удельный вес среднего отклонения (линейного или квадратического) в среднем арифметическом показателе, выраженном в процентах, т.е. рассчитать относительные показатели вариации.
Линейный коэффициент вариации вычисляют по формуле
Коэффициент вариации определяют по следующей формуле:
В коэффициентах вариации устраняется не только несопоставимость, связанная с различными единицами измерения изучаемого признака, но и несопоставимость, возникающая вследствие различий в величине средних арифметических. Кроме того, показатели вариации дают характеристику однородности совокупности. Совокупность считается однородной, если коэффициент вариации не превышает 33%.
По данным табл. 6.2 и полученным выше результатам расчетов определим коэффициент вариации, %, по формуле (6.3):
![]()
Если коэффициент вариации превышает 33%, то это свидетельствует о неоднородности изучаемой совокупности. Полученное в пашем случае значение говорит о том, что совокупность студентов по возрасту однородна по своему составу. Таким образом, важная функция обобщающих показателей вариации - оценка надежности средних. Чем меньше с1, а2 и V, тем однороднее полученная совокупность явлений и надежнее полученная средняя. Согласно рассматриваемому математической статистикой "правилу трех сигм" в нормально распределенных или близких к ним рядах отклонения от средней арифметической, не превосходящие ±3ст, встречаются в 997 случаях из 1000. Таким образом, зная х и а, можно получить общее первоначальное представление о вариационном ряде. Если, например, средняя заработная плата работника по фирме составила 25 000 руб., а а равна 100 руб., то с вероятностью, близкой к достоверности, можно утверждать, что заработная плата работников фирмы колеблется в пределах (25 000 ± ± 3 х 100) т.е. от 24 700 до 25 300 руб.
$X$. Для начала напомним следующее определение:
Определение 1
Генеральная совокупность -- совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Определение 2
Генеральная дисперсия -- среднее арифметическое квадратов отклонений значений вариант генеральной совокупности от их среднего значения.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда генеральная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае генеральная дисперсия вычисляется по формуле:
С этим понятием также связано понятие генерального среднего квадратического отклонения.
Определение 3
Генеральное среднее квадратическое отклонение
\[{\sigma }_г=\sqrt{D_г}\]
Выборочная дисперсия
Пусть нам дана выборочная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 4
Выборочная совокупность -- часть отобранных объектов из генеральной совокупности.
Определение 5
Выборочная дисперсия -- среднее арифметическое значений вариант выборочной совокупности.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда выборочная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае выборочная дисперсия вычисляется по формуле:
С этим понятием также связано понятие выборочного среднего квадратического отклонения.
Определение 6
Выборочное среднее квадратическое отклонение -- квадратный корень из генеральной дисперсии:
\[{\sigma }_в=\sqrt{D_в}\]
Исправленная дисперсия
Для нахождения исправленной дисперсии $S^2$ необходимо умножить выборочную дисперсию на дробь $\frac{n}{n-1}$, то есть
С этим понятием также связано понятие исправленного среднего квадратического отклонения, которое находится по формуле:
В случае, когда значение вариант не являются дискретными, а представляют из себя интервалы, то в формулах для вычисления генеральной или выборочной дисперсий за значение $x_i$ принимается значение середины интервала, которому принадлежит $x_i.$
Пример задачи на нахождение дисперсии и среднего квадратического отклонения
Пример 1
Выборочная совокупность задана следующей таблицей распределения:
Рисунок 1.
Найдем для нее выборочную дисперсию, выборочное среднее квадратическое отклонение, исправленную дисперсию и исправленное среднее квадратическое отклонение.
Для решения этой задачи для начала сделаем расчетную таблицу:
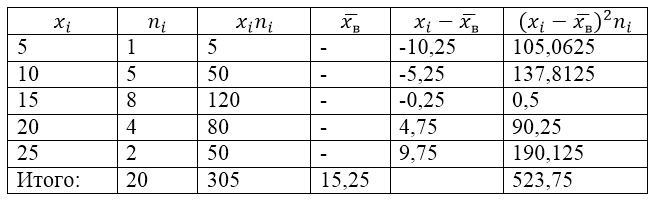
Рисунок 2.
Величина $\overline{x_в}$ (среднее выборочное) в таблице находится по формуле:
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}\]
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}=\frac{305}{20}=15,25\]
Найдем выборочную дисперсию по формуле:
Выборочное среднее квадратическое отклонение:
\[{\sigma }_в=\sqrt{D_в}\approx 5,12\]
Исправленная дисперсия:
\[{S^2=\frac{n}{n-1}D}_в=\frac{20}{19}\cdot 26,1875\approx 27,57\]
Исправленное среднее квадратическое отклонение.
При статистической проверке гипотез, при измерении линейной взаимосвязи между случайными величинами.
Среднеквадратическое отклонение:
Стандартное отклонение (оценка среднеквадратического отклонения случайной величины Пол, стены вокруг нас и потолок,x относительно её математического ожидания на основе несмещённой оценки её дисперсии):
где - дисперсия ; - Пол, стены вокруг нас и потолок,i -й элемент выборки; - объём выборки; - среднее арифметическое выборки:
Следует отметить, что обе оценки являются смещёнными. В общем случае несмещённую оценку построить невозможно. Однако оценка на основе оценки несмещённой дисперсии является состоятельной .
Правило трёх сигм
Правило трёх сигм () - практически все значения нормально распределённой случайной величины лежат в интервале . Более строго - не менее чем с 99,7 % достоверностью значение нормально распределенной случайной величины лежит в указанном интервале (при условии, что величина истинная, а не полученная в результате обработки выборки).
Если же истинная величина неизвестна, то следует пользоваться не , а Пол, стены вокруг нас и потолок,s . Таким образом, правило трёх сигм преобразуется в правило трёх Пол, стены вокруг нас и потолок,s .
Интерпретация величины среднеквадратического отклонения
Большое значение среднеквадратического отклонения показывает большой разброс значений в представленном множестве со средней величиной множества; маленькое значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Например, у нас есть три числовых множества: {0, 0, 14, 14}, {0, 6, 8, 14} и {6, 6, 8, 8}. У всех трёх множеств средние значения равны 7, а среднеквадратические отклонения, соответственно, равны 7, 5 и 1. У последнего множества среднеквадратическое отклонение маленькое, так как значения в множестве сгруппированы вокруг среднего значения; у первого множества самое большое значение среднеквадратического отклонения - значения внутри множества сильно расходятся со средним значением.
В общем смысле среднеквадратическое отклонение можно считать мерой неопределенности. К примеру, в физике среднеквадратическое отклонение используется для определения погрешности серии последовательных измерений какой-либо величины. Это значение очень важно для определения правдоподобности изучаемого явления в сравнении с предсказанным теорией значением: если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратического отклонения), то полученные значения или метод их получения следует перепроверить.
Практическое применение
На практике среднеквадратическое отклонение позволяет определить, насколько значения в множестве могут отличаться от среднего значения.
Климат
Предположим, существуют два города с одинаковой средней максимальной дневной температурой, но один расположен на побережье, а другой внутри континента. Известно, что в городах, расположенных на побережье, множество различных максимальных дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднеквадратическое отклонение максимальных дневных температур у прибрежного города будет меньше, чем у второго города, несмотря на то, что среднее значение этой величины у них одинаковое, что на практике означает, что вероятность того, что максимальная температура воздуха каждого конкретного дня в году будет сильнее отличаться от среднего значения, выше у города, расположенного внутри континента.
Спорт
Предположим, что есть несколько футбольных команд, которые оцениваются по некоторому набору параметров, например, количеству забитых и пропущенных голов, голевых моментов и т. п. Наиболее вероятно, что лучшая в этой группе команда будет иметь лучшие значения по большему количеству параметров. Чем меньше у команды среднеквадратическое отклонение по каждому из представленных параметров, тем предсказуемее является результат команды, такие команды являются сбалансированными. С другой стороны, у команды с большим значением среднеквадратического отклонения сложно предсказать результат, что в свою очередь объясняется дисбалансом, например, сильной защитой, но слабым нападением.
Использование среднеквадратического отклонения параметров команды позволяет в той или иной мере предсказать результат матча двух команд, оценивая сильные и слабые стороны команд, а значит, и выбираемых способов борьбы.
Технический анализ
См. также
Литература
| Эта статья предлагается к удалению.
Пояснение причин и соответствующее обсуждение вы можете найти на странице Википедия:К удалению/17 декабря 2012.
|
* Боровиков, В. STATISTICA. Искусство анализа данных на компьютере: Для профессионалов / В. Боровиков. - СПб. : Питер, 2003. - 688 с. - ISBN 5-272-00078-1 .
| Статистические показатели | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Описательная статистика |
|
||||||||||
| Статистический вывод и проверка гипотез |
| ||||||||||
Х i - случайные (текущие) величины;
X̅ – среднее значение случайных величин по выборке, рассчитывается по формуле:

Итак, дисперсия - это средний квадрат отклонений . То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат , складывается и затем делится на количество значений в данной совокупности.
Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, мы просто рассчитываем среднюю арифметическую.
Разгадка магического слова «дисперсия» заключается всего в этих трех словах: средний – квадрат – отклонений.
Среднее квадратичное отклонение (СКО)
Извлекая из дисперсии квадратный корень, получаем, так называемое «среднеквадратичное отклонение». Встречаются названия «стандартное отклонение» или «сигма» (от названия греческой буквыσ .). Формула среднего квадратичного отклонения имеет вид:
Итак, дисперсия – это сигма в квадрате, или – среднее квадратичное отклонение в квадрате.
Среднеквадратичное отклонение, очевидно, также характеризует меру рассеивания данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными, так как единицы измерения у них одинаковые (это явствует из формулы расчета). Размах вариации – это разница между крайними значениями. Среднеквадратичное отклонение, как мера неопределенности, также участвует во многих статистических расчетах. С ее помощью устанавливают степень точности различных оценок и прогнозов. Если вариация очень большая, то стандартное отклонение тоже получится большим, следовательно, и прогноз будет неточным, что выразится, к примеру, в очень широких доверительных интервалах.
Поэтому в методах статистической обработки данных в оценках объектов недвижимости в зависимости от необходимой точности поставленной задачи используют правило двух или трех сигм.
Для сравнения правила двух сигм и правила трех сигм используем формулу Лапласа:
![]() Ф - Ф ,
Ф - Ф ,
где Ф(x) – функция Лапласа;
Минимальное значение
β = максимальное значение
s = значение сигмы (среднее квадратичное отклонение)
a = среднее значение
В этом случае используется частный вид формулы Лапласа когда границы α и β значений случайной величины X равно отстоят от центра распределения a = M(X) на некоторую величину d: a = a-d, b = a+d.
 Или
Или
  (1)
Формула (1) определяет вероятность заданного отклонения d случайной величины X с нормальным законом распределения от ее математического ожидания М(X) = a.
Если в формуле (1) принять последовательно d = 2s и d = 3s, то получим:
(2),
(3). (1)
Формула (1) определяет вероятность заданного отклонения d случайной величины X с нормальным законом распределения от ее математического ожидания М(X) = a.
Если в формуле (1) принять последовательно d = 2s и d = 3s, то получим:
(2),
(3).
|
Правило двух сигм
Почти достоверно (с доверительной вероятностью 0,954) можно утверждать, что все значения случайной величины X с нормальным законом распределения отклоняются от ее математического ожидания M(X) = a на величину, не большую 2s (двух средних квадратических отклонений). Доверительной вероятностью (Pд) называют вероятность событий, которые условно принимаются за достоверные (их вероятность близка к 1).
Проиллюстрируем правило двух сигм геометрически. На рис. 6 изображена кривая Гаусса с центром распределения а. Площадь, ограниченная всей кривой и осью Оx, равна 1 (100%), а площадь криволинейной трапеции между абсциссами а–2s и а+2s, согласно правилу двух сигм, равна 0,954 (95,4% от всей площади). Площадь заштрихованных участков равна 1-0,954 = 0,046 (»5% от всей площади). Эти участки называют критической областью значений случайной величины. Значения случайной величины, попадающие в критическую область, маловероятны и на практике условно принимаются за невозможные.

Вероятность условно невозможных значений называют уровнем значимости случайной величины. Уровень значимости связан с доверительной вероятностью формулой:
где q – уровень значимости, выраженный в процентах.
Правило трех сигм
При решении вопросов, требующих большей надежности, когда доверительную вероятность (Pд) принимают равной 0,997 (точнее - 0,9973), вместо правила двух сигм, согласно формуле (3), используют правило трех сигм.
Согласно правилу трех сигм при доверительной вероятности 0,9973 критической областью будет область значений признака вне интервала (а-3s, а+3s). Уровень значимости составляет 0,27%.
Другими словами, вероятность того, что абсолютная величина отклонения превысит утроенное среднее квадратическое отклонение, очень мала, а именно равна 0,0027=1-0,9973. Это означает, что лишь в 0,27% случаев так может произойти. Такие события, исходя из принципа невозможности маловероятных событий, можно считать практически невозможными. Т.е. выборка высокоточная.
В этом и состоит сущность правила трех сигм:
Если случайная величина распределена нормально, то абсолютная величина ее отклонения от математического ожидания не превосходит утроенного среднего квадратического отклонения (СКО).
На практике правило трех сигм применяют так: если распределение изучаемой случайной величины неизвестно, но условие, указанное в приведенном правиле, выполняется, то есть основание предполагать, что изучаемая величина распределена нормально; в противном случае она не распределена нормально.
Уровень значимости принимают в зависимости от дозволенной степени риска и поставленной задачи. Для оценки недвижимости обычно принимается менее точная выборка, следуя правилу двух сигм.







