
In this syntax, Oracle compares the input expression (e) to each comparison expression e1, e2, …, en.
If the input expression equals any comparison expression, the CASE expression returns the corresponding result expression (r).
If the input expression e does not match any comparison expression, the CASE expression returns the expression in the ELSE clause if the ELSE clause exists, otherwise, it returns a null value.
Oracle uses short-circuit evaluation for the simple CASE expression. It means that Oracle evaluates each comparison expression (e1, e2, .. en) only before comparing one of them with the input expression (e). Oracle does not evaluate all comparison expressions before comparing any of them with the expression (e). As a result, Oracle never evaluates a comparison expression if a previous one equals the input expression (e).
Simple CASE expression example
We will use the products table in the for the demonstration.
The following query uses the CASE expression to calculate the discount for each product category i.e., CPU 5%, video card 10%, and other product categories 8%
SELECT CASE category_id WHEN 1 THEN ROUND (list_price*0.05,2)-- CPU WHEN 2 THEN ROUND (List_price*0.1,2)-- Video Card ELSE ROUND (list_price*0.08,2)-- other categories END discount FROM ORDER BY |
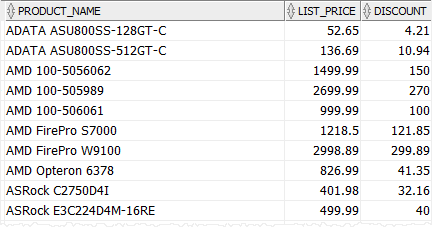
Note that we used the ROUND () function to round the discount to two decimal places.
Searched CASE expression
The Oracle searched CASE expression evaluates a list of Boolean expressions to determine the result.
The searched CASE statement has the following syntax:
CASE WHEN e1THEN r1 WHEN condition_1 THEN result_1 WHEN condition_2 THEN result_2 ... WHEN condition_n THEN result_n ELSE result END Parameters or Argumentsexpression Optional. It is the value that you are comparing to the list of conditions. (ie: condition_1, condition_2, ... condition_n) condition_1, condition_2, ... condition_n The conditions that must all be the same datatype. The conditions are evaluated in the order listed. Once a condition is found to be true, the CASE statement will return the result and not evaluate the conditions any further. result_1, result_2, ... result_n Results that must all be the same datatype. This is the value returned once a condition is found to be true.ReturnsThe CASE statement returns any datatype such as a string, numeric, date, etc. (BUT all results must be the same datatype in the CASE statement.) Note
Applies ToThe CASE statement can be used in the following versions of Oracle/PLSQL:
ExampleThe CASE statement can be used in Oracle/PLSQL. You could use the CASE statement in a SQL statement as follows: (includes the expression clause) SELECT table_name, CASE owner WHEN "SYS" THEN "The owner is SYS" WHEN "SYSTEM" THEN "The owner is SYSTEM" ELSE "The owner is another value" END FROM all_tables; Or you could write the SQL statement using the CASE statement like this: (omits the expression clause) SELECT table_name, CASE WHEN owner="SYS" THEN "The owner is SYS" WHEN owner="SYSTEM" THEN "The owner is SYSTEM" ELSE "The owner is another value" END FROM all_tables; The above two CASE statements are equivalent to the following IF-THEN-ELSE statement: IF owner = "SYS" THEN result:= "The owner is SYS"; ELSIF owner = "SYSTEM" THEN result:= "The owner is SYSTEM""; ELSE result:= "The owner is another value"; END IF; The CASE statement will compare each owner value, one by one. One thing to note is that the ELSE clause within the CASE statement is optional. You could have omitted it. Let"s look at the SQL statement above with the ELSE clause omitted. Your SQL statement would look as follows: SELECT table_name, CASE owner WHEN "SYS" THEN "The owner is SYS" WHEN "SYSTEM" THEN "The owner is SYSTEM" END FROM all_tables; With the ELSE clause omitted, if no condition was found to be true, the CASE statement would return NULL. Comparing 2 ConditionsHere is an example that demonstrates how to use the CASE statement to compare different conditions: SELECT CASE WHEN a < b THEN "hello" WHEN d < e THEN "goodbye" END FROM suppliers; Frequently Asked QuestionsQuestion: Can you create a CASE statement that evaluates two different fields? I want to return a value based on the combinations in two different fields. Answer: Yes, below is an example of a case statement that evaluates two different fields. SELECT supplier_id, CASE WHEN supplier_name = "IBM" and supplier_type = "Hardware" THEN "North office" WHEN supplier_name = "IBM" and supplier_type = "Software" THEN "South office" END FROM suppliers; So if supplier_name field is IBM and the supplier_type field is Hardware , then the CASE statement will return North office . If the supplier_name field is IBM and the supplier_type is Software , the CASE statement will return South office . Команда CASE позволяет выбрать для выполнения одну из нескольких последовательностей команд . Эта конструкция присутствует в стандарте SQL с 1992 года, хотя в Oracle SQL она не поддерживалась вплоть до версии Oracle8i, а в PL/SQL - до версии Oracle9i Release 1. Начиная с этой версии, поддерживаются следующие разновидности команд CASE:
NULL или UNKNOWN?В статье, посвященной оператору IF , вы могли узнать, что результат логического выражения может быть равен TRUE , FALSE или NULL . В PL/SQL это утверждение истинно, но в более широком контексте реляционной теории считается некорректным говорить о возврате NULL из логического выражения. Реляционная теория говорит, что сравнение с NULL следующего вида: 2 < NULL дает логический результат UNKNOWN , причем значение UNKNOWN не эквивалентно NULL . Впрочем, вам не стоит особенно переживать из-за того, что в PL/SQL для UNKNOWN используется обозначение NULL . Однако вам следует знать, что третьим значением в трехзначной логике является UNKNOWN . И я надеюсь, что вы никогда не попадете впросак (как это бывало со мной!), используя неправильный термин при обсуждении трехзначной логики с экспертами в области реляционной теории. Кроме команд CASE , PL/SQL также поддерживает CASE -выражения. Такое выражение очень похоже на команду CASE , оно позволяет выбрать для вычисления одно или несколько выражений. Результатом выражения CASE является одно значение, тогда как результатом команды CASE является выполнение последовательности команд PL/SQL. Простые команды CASEПростая команда CASE позволяет выбрать для выполнения одну из нескольких последовательностей команд PL/SQL в зависимости от результата вычисления выражения. Он записывается следующим образом: CASE выражение WHEN результат_1 THEN команды_1 WHEN результат_2 THEN команды_2 ... ELSE команды_else END CASE; Ветвь ELSE здесь не обязательна. При выполнении такой команды PL/SQL сначала вычисляет выражение, после чего результат сравнивается с результат_1 . Если они совпадают, то выполняются команды_1 . В противном случае проверяется значение результат_2 и т. д. Приведем пример простой команды CASE , в котором премия начисляется в зависимости от значения переменной employee_type: CASE employee_type WHEN "S" THEN award_salary_bonus(employee_id); WHEN "H" THEN award_hourly_bonus(employee_id); WHEN "C" THEN award_commissioned_bonus(employee_id); ELSE RAISE invalid_employee_type; END CASE; В этом примере присутствует явно заданная секция ELSE , однако в общем случае она не обязательна. Без секции ELSE компилятор PL/SQL неявно подставляет такой код: ELSE RAISE CASE_NOT_FOUND; Иначе говоря, если не задать ключевое слово ELSE и если никакой из результатов в секциях WHEN не соответствует результату выражения в команде CASE , PL/SQL инициирует исключение CASE_NOT_FOUND . В этом и заключается отличие данной команды от IF . Когда в команде IF отсутствует ключевое слово ELSE , то при невыполнении условия не происходит ничего, тогда как в команде CASE аналогичная ситуация приводит к ошибке. Интересно посмотреть, как с помощью простой команды CASE реализовать описанную в начале главы логику начисления премий. На первый взгляд это кажется невозможным, но подойдя к делу творчески, мы приходим к следующему решению: CASE TRUE WHEN salary >= 10000 AND salary <=20000 THEN give_bonus(employee_id, 1500); WHEN salary > 20000 AND salary <= 40000 THEN give_bonus(employee_id, 1000); WHEN salary > 40000 THEN give_bonus(employee_id, 500); ELSE give_bonus(employee_id, 0); END CASE; Здесь важно то, что элементы выражение и результат могут быть либо скалярными значениями, либо выражениями, результатами которых являются скалярные значения. Вернувшись к команде IF...THEN...ELSIF , реализующей ту же логику, вы увидите, что в команде CASE определена секция ELSE , тогда как в команде IF–THEN–ELSIF ключевое слово ELSE отсутствует. Причина добавления ELSE проста: если ни одно из условий начисления премии не выполняется, команда IF ничего не делает, и премия получается нулевой. Команда CASE в этом случае выдает ошибку, поэтому ситуацию с нулевым размером премии приходится программировать явно. Чтобы предотвратить ошибки CASE_NOT_FOUND , убедитесь в том, что при любом значении проверяемого выражения будет выполнено хотя бы одно из условий. Приведенная выше команда CASE TRUE кому-то покажется эффектным трюком, но на самом деле она всего лишь реализует поисковую команду CASE , о которой мы поговорим в следующем разделе. Поисковая команда CASEПоисковая команда CASE проверяет список логических выражений; обнаружив выражение, равное TRUE , выполняет последовательность связанных с ним команд. В сущности, поисковая команда CASE является аналогом команды CASE TRUE , пример которой приведен в предыдущем разделе. Поисковая команда CASE имеет следующую форму записи: CASE WHEN выражение_1 THEN команды_1 WHEN выражение_2 THEN команда_2 ... ELSE команды_else END CASE; Она идеально подходит для реализации логики начисления премии: CASE WHEN salary >= 10000 AND salary <=20000 THEN give_bonus(employee_id, 1500); WHEN salary > 20000 AND salary <= 40000 THEN give_bonus(employee_id, 1000); WHEN salary > 40000 THEN give_bonus(employee_id, 500); ELSE give_bonus(employee_id, 0); END CASE; Поисковая команда CASE , как и простая команда, подчиняется следующим правилам:
Рассмотрим еще одну реализацию логики начисления премии, в которой используется то обстоятельство, что условия WHEN проверяются в порядке их записи. Отдельные выражения проще, но можно ли сказать, что смысл всей команды стал более понятным? CASE WHEN salary > 40000 THEN give_bonus(employee_id, 500); WHEN salary > 20000 THEN give_bonus(employee_id, 1000); WHEN salary >= 10000 THEN give_bonus(employee_id, 1500); ELSE give_bonus(employee_id, 0); END CASE; Если оклад некоего сотрудника равен 20 000, то первые два условия равны FALSE , а третье - TRUE , поэтому сотрудник получит премию в 1500 долларов. Если же оклад равен 21 000, то результат второго условия будет равен TRUE , и премия составит 1000 долларов. Выполнение команды CASE завершится на второй ветви WHEN , а третье условие даже не будет проверяться. Стоит ли использовать такой подход при написании команд CASE - вопрос спорный. Как бы то ни было, имейте в виду, что написать такую команду возможно, а при отладке и редактировании программ, в которых результат зависит от порядка следования выражений, необходима особая внимательность. Логика, зависящая от порядка следования однородных ветвей WHEN , является потенциальным источником ошибок, возникающих при их перестановке. В качестве примера рассмотрим следующую поисковую команду CASE , в которой при значении salary , равном 20 000, проверка условий в обеих ветвях WHEN дает TRUE: CASE WHEN salary BETWEEN 10000 AND 20000 THEN give_bonus(employee_id, 1500); WHEN salary BETWEEN 20000 AND 40000 THEN give_bonus(employee_id, 1000); ... Представьте, что программист, занимающийся сопровождением этой программы, легкомысленно переставит ветви WHEN , чтобы упорядочить их по убыванию salary . Не отвергайте такую возможность! Программисты часто склонны «доводить до ума» прекрасно работающий код, руководствуясь какими-то внутренними представлениями о порядке. Команда CASE с переставленными секциями WHEN выглядит так: CASE WHEN salary BETWEEN 20000 AND 40000 THEN give_bonus(employee_id, 1000); WHEN salary BETWEEN 10000 AND 20000 THEN give_bonus(employee_id, 1500); ... На первый взгляд все верно, не так ли? К сожалению, из-за перекрытия двух ветвей WHEN в программе появляется коварная ошибка. Теперь сотрудник с окладом 20 000 получит премию 1000 вместо положенных 1500. Возможно, в некоторых ситуациях перекрытие между ветвями WHEN желательно и все же его следует по возможности избегать. Всегда помните, что порядок следования ветвей важен, и сдерживайте желание доработать уже работающий код - «не чините то, что не сломано». Поскольку условия WHEN проверяются по порядку, можно немного повысить эффективность кода, поместив ветви с наиболее вероятными условиями в начало списка. Кроме того, если у вас есть ветвь с «затратными» выражениями (например, требующими значительного процессорного времени и памяти), их можно поместить в конец, чтобы свести к минимуму вероятность их проверки. За подробностями обращайтесь к разделу «Вложенные команды IF ». Поисковые команды CASE используются в тех случаях, когда выполняемые команды определяются набором логических выражений. Простая команда CASE используется тогда, когда решение принимается на основании результата одного выражения.
Вложенные команды CASEКоманды CASE , как и команды IF , могут быть вложенными. Например, вложенная команда CASE присутствует в следующей (довольно запутанной) реализации логики начисления премий: CASE WHEN salary >= 10000 THEN CASE WHEN salary <= 20000 THEN give_bonus(employee_id, 1500); WHEN salary > 40000 THEN give_bonus(employee_id, 500); WHEN salary > 20000 THEN give_bonus(employee_id, 1000); END CASE; WHEN salary < 10000 THEN give_bonus(employee_id,0); END CASE; В команде CASE могут использоваться любые команды, так что внутренняя команда CASE легко заменяется командой IF . Аналогичным образом, в команду IF может быть вложена любая команда, в том числе и CASE . Выражения CASEВыражения CASE решают ту же задачу, что и команды CASE , но только не для исполняемых команд, а для выражений. Простое выражение CASE выбирает для вычисления одно из нескольких выражений на основании заданного скалярного значения. Поисковое выражение CASE последовательно вычисляет выражения из списка, пока одно из них не окажется равным TRUE , а затем возвращает результат связанного с ним выражения. Синтаксис этих двух разновидностей выражений CASE: Простое_выражение_Case:= CASE выражение WHEN результат_1 THEN результирующее_выражение_1 WHEN результат_2 THEN результирующее_выражение_2 ... ELSE результирующее_выражение_else END; Поисковое_выражение_Case:= CASE WHEN выражение_1 THEN результирующее_выражение_1 WHEN выражение_2 THEN результирующее_выражение_2 ... ELSE результирующее_выражение_else END; Выражение CASE возвращает одно значение - результат выбранного для вычисления выражения. Каждой ветви WHEN должно быть поставлено в соответствие одно результирующее выражение (но не команда). В конце выражения CASE не ставится ни точка с запятой, ни END CASE . Выражение CASE завершается ключевым словом END . Далее приводится пример простого выражения CASE , используемого совместно с процедурой PUT_LINE пакета DBMS_OUTPUT для вывода на экран значения логической переменной. DECLARE boolean_true BOOLEAN:= TRUE; boolean_false BOOLEAN:= FALSE; boolean_null BOOLEAN; FUNCTION boolean_to_varchar2 (flag IN BOOLEAN) RETURN VARCHAR2 IS BEGIN RETURN CASE flag WHEN TRUE THEN "True" WHEN FALSE THEN "False" ELSE "NULL" END; END; BEGIN DBMS_OUTPUT.PUT_LINE(boolean_to_varchar2(boolean_true)); DBMS_OUTPUT.PUT_LINE(boolean_to_varchar2(boolean_false)); DBMS_OUTPUT.PUT_LINE(boolean_to_varchar2(boolean_null)); END; Для реализации логики начисления премий можно использовать поисковое выражение CASE , возвращающее величину премии для заданного оклада: DECLARE salary NUMBER:= 20000; employee_id NUMBER:= 36325; PROCEDURE give_bonus (emp_id IN NUMBER, bonus_amt IN NUMBER) IS BEGIN DBMS_OUTPUT.PUT_LINE(emp_id); DBMS_OUTPUT.PUT_LINE(bonus_amt); END; BEGIN give_bonus(employee_id, CASE WHEN salary >= 10000 AND salary <= 20000 THEN 1500 WHEN salary > 20000 AND salary <= 40000 THEN 1000 WHEN salary > 40000 THEN 500 ELSE 0 END); END; Выражение CASE может применяться везде, где допускается использование выражений любого другого типа. В следующем примере CASE-выражение используется для вычисления размера премии, умножения его на 10 и присваивания результата переменной, выводимой на экран средствами DBMS_OUTPUT: DECLARE salary NUMBER:= 20000; employee_id NUMBER:= 36325; bonus_amount NUMBER; BEGIN bonus_amount:= CASE WHEN salary >= 10000 AND salary <= 20000 THEN 1500 WHEN salary > 20000 AND salary <= 40000 THEN 1000 WHEN salary > 40000 THEN 500 ELSE 0 END * 10; DBMS_OUTPUT.PUT_LINE(bonus_amount); END; В отличие от команды CASE , если условие ни одной ветви WHEN не выполнено, выражение CASE не выдает ошибку, а просто возвращает NULL .
О чем будет рассказано в этой частиВ этой части мы познакомимся:
Выражение CASE – условный оператор языка SQLДанный оператор позволяет осуществить проверку условий и возвратить в зависимости от выполнения того или иного условия тот или иной результат.Оператор CASE имеет 2 формы: Разберем на примере первую форму CASE: SELECT
ID,Name,Salary,
CASE
WHEN Salary>=3000 THEN "ЗП >= 3000"
WHEN Salary>=2000 THEN "2000 <= ЗП < 3000"
ELSE "ЗП < 2000"
END SalaryTypeWithELSE,
CASE
WHEN Salary>=3000 THEN "ЗП >= 3000"
WHEN Salary>=2000 THEN "2000 <= ЗП < 3000"
END SalaryTypeWithoutELSE
FROM Employees
Если ни одно из WHEN-условий не выполняется, то возвращается значение, указанное после слова ELSE (что в данном случае означает «ИНАЧЕ ВЕРНИ …»). Если ELSE-блок не указан и не выполняется ни одно WHEN-условие, то возвращается NULL. И в первой, и во второй форме ELSE-блок идет в самом конце конструкции CASE, т.е. после всех WHEN-условий. Разберем на примере вторую форму CASE: Допустим, на новый год решили премировать всех сотрудников и попросили вычислить сумму бонусов по следующей схеме:
Используем для данной задачи запрос с выражением CASE: SELECT
ID,Name,Salary,DepartmentID,
-- для наглядности выведем процент в виде строки
CASE DepartmentID -- проверяемое значение
WHEN 2 THEN "10%" -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN "15%" -- 15% от ЗП выдать ИТ-шникам
ELSE "5%" -- всем остальным по 5%
END NewYearBonusPercent,
-- построим выражение с использованием CASE, чтобы увидеть сумму бонуса
Salary/100*
CASE DepartmentID
WHEN 2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusAmount
FROM Employees
Соответственно, значение блока ELSE возвращается в случае, если DepartmentID не совпал ни с одним WHEN-значением. Если блок ELSE отсутствует, то в случае несовпадения DepartmentID ни с одним WHEN-значением будет возвращено NULL. Вторую форму CASE несложно представить при помощи первой формы: SELECT ID,Name,Salary,DepartmentID, CASE WHEN DepartmentID=2 THEN "10%" -- 10% от ЗП выдать Бухгалтерам WHEN DepartmentID=3 THEN "15%" -- 15% от ЗП выдать ИТ-шникам ELSE "5%" -- всем остальным по 5% END NewYearBonusPercent, -- построим выражение с использованием CASE, чтобы увидеть сумму бонуса Salary/100* CASE WHEN DepartmentID=2 THEN 10 -- 10% от ЗП выдать Бухгалтерам WHEN DepartmentID=3 THEN 15 -- 15% от ЗП выдать ИТ-шникам ELSE 5 -- всем остальным по 5% END BonusAmount FROM Employees Так что, вторая форма – это всего лишь упрощенная запись для тех случаев, когда нам нужно сделать сравнение на равенство, одного и того же проверяемого значения с каждым WHEN-значением/выражением. Примечание. Первая и вторая форма CASE входят в стандарт языка SQL, поэтому скорее всего они должны быть применимы во многих СУБД. С MS SQL версии 2012 появилась упрощенная форма записи IIF. Она может использоваться для упрощенной записи конструкции CASE, в том случае если возвращаются только 2 значения. Конструкция IIF имеет следующий вид: IIF(условие, true_значение, false_значение) Т.е. по сути это обертка для следующей CASE конструкции: CASE WHEN условие THEN true_значение ELSE false_значение END Посмотрим на примере: SELECT ID,Name,Salary, IIF(Salary>=2500,"ЗП >= 2500","ЗП < 2500") DemoIIF, CASE WHEN Salary>=2500 THEN "ЗП >= 2500" ELSE "ЗП < 2500" END DemoCASE FROM Employees Конструкции CASE, IIF могут быть вложенными друг в друга. Рассмотрим абстрактный пример: SELECT ID,Name,Salary, CASE WHEN DepartmentID IN(1,2) THEN "A" WHEN DepartmentID=3 THEN CASE PositionID -- вложенный CASE WHEN 3 THEN "B-1" WHEN 4 THEN "B-2" END ELSE "C" END Demo1, IIF(DepartmentID IN(1,2),"A", IIF(DepartmentID=3,CASE PositionID WHEN 3 THEN "B-1" WHEN 4 THEN "B-2" END,"C")) Demo2 FROM Employees Так как конструкция CASE и IIF представляют из себя выражение, которые возвращают результат, то мы можем использовать их не только в блоке SELECT, но и в остальных блоках, допускающих использование выражений, например, в блоках WHERE или ORDER BY. Для примера, пускай перед нами поставили задачу – создать список на выдачу ЗП на руки, следующим образом:
Попробуем решить эту задачу при помощи добавления CASE-выражение в блок ORDER BY: SELECT
ID,Name,Salary
FROM Employees
ORDER BY
CASE WHEN Salary>=2500 THEN 1 ELSE 0 END, -- выдать ЗП сначала тем у кого она ниже 2500
Name -- дальше упорядочить список в порядке ФИО
И абстрактный пример использования CASE в блоке WHERE: SELECT ID,Name,Salary FROM Employees WHERE CASE WHEN Salary>=2500 THEN 1 ELSE 0 END=1 -- все записи у которых выражение равно 1 Можете попытаться самостоятельно переделать 2 последних примера с функцией IIF. И напоследок, вспомним еще раз о NULL-значениях: SELECT
ID,Name,Salary,DepartmentID,
CASE
WHEN DepartmentID=2 THEN "10%" -- 10% от ЗП выдать Бухгалтерам
WHEN DepartmentID=3 THEN "15%" -- 15% от ЗП выдать ИТ-шникам
WHEN DepartmentID IS NULL THEN "-" -- внештатникам бонусов не даем (используем IS NULL)
ELSE "5%" -- всем остальным по 5%
END NewYearBonusPercent1,
-- а так проверять на NULL нельзя, вспоминаем что говорилось про NULL во второй части
CASE DepartmentID -- проверяемое значение
WHEN 2 THEN "10%"
WHEN 3 THEN "15%"
WHEN NULL THEN "-" -- !!! в данном случае использование второй формы CASE не подходит
ELSE "5%"
END NewYearBonusPercent2
FROM Employees
SELECT ID,Name,Salary,DepartmentID, CASE ISNULL(DepartmentID,-1) -- используем замену в случае NULL на -1 WHEN 2 THEN "10%" WHEN 3 THEN "15%" WHEN -1 THEN "-" -- если мы уверены, что отдела с ID равным (-1) нет и не будет ELSE "5%" END NewYearBonusPercent3 FROM Employees В общем, полет фантазии в данном случае не ограничен. Для примера посмотрим, как при помощи CASE и IIF можно смоделировать функцию ISNULL: SELECT ID,Name,LastName, ISNULL(LastName,"Не указано") DemoISNULL, CASE WHEN LastName IS NULL THEN "Не указано" ELSE LastName END DemoCASE, IIF(LastName IS NULL,"Не указано",LastName) DemoIIF FROM Employees Конструкция CASE очень мощное средство языка SQL, которое позволяет наложить дополнительную логику для расчета значений результирующего набора. В данной части владение CASE-конструкцией нам еще пригодится, поэтому в этой части в первую очередь внимание уделено именно ей. Агрегатные функцииЗдесь мы рассмотрим только основные и наиболее часто используемые агрегатные функции:
Агрегатные функции позволяют нам сделать расчет итогового значения для набора строк полученных при помощи оператора SELECT. Рассмотрим каждую функцию на примере: SELECT
COUNT(*) [Общее кол-во сотрудников],
COUNT(DISTINCT DepartmentID) [Число уникальных отделов],
COUNT(DISTINCT PositionID) [Число уникальных должностей],
COUNT(BonusPercent) [Кол-во сотрудников у которых указан % бонуса],
MAX(BonusPercent) [Максимальный процент бонуса],
MIN(BonusPercent) [Минимальный процент бонуса],
SUM(Salary/100*BonusPercent) [Сумма всех бонусов],
AVG(Salary/100*BonusPercent) [Средний размер бонуса],
AVG(Salary) [Средний размер ЗП]
FROM Employees
Разберем каким образом получилось каждое возвращенное значение, а за одно вспомним конструкции базового синтаксиса оператора SELECT. Во-первых, т.к. мы в запросе не указали WHERE-условия, то итоги будут считаться для детальных данных, которые получаются запросом: SELECT * FROM Employees Т.е. для всех строк таблицы Employees. Для наглядности выберем только поля и выражения, которые используются в агрегатных функциях: SELECT
DepartmentID,
PositionID,
BonusPercent,
Salary/100*BonusPercent ,
Salary
FROM Employees
Это исходные данные (детальные строки), по которым и будут считаться итоги агрегированного запроса. Теперь разберем каждое агрегированное значение:
Подведем некоторые итоги:
Соответственно при задании с агрегатными функциями дополнительного условия в блоке WHERE, будут подсчитаны только итоги, по строкам удовлетворяющих условию. Т.е. расчет агрегатных значений происходит для итогового набора, который получен при помощи конструкции SELECT. Например, сделаем все тоже самое, но только в разрезе ИТ-отдела: SELECT
COUNT(*) [Общее кол-во сотрудников],
COUNT(DISTINCT DepartmentID) [Число уникальных отделов],
COUNT(DISTINCT PositionID) [Число уникальных должностей],
COUNT(BonusPercent) [Кол-во сотрудников у которых указан % бонуса],
MAX(BonusPercent) [Максимальный процент бонуса],
MIN(BonusPercent) [Минимальный процент бонуса],
SUM(Salary/100*BonusPercent) [Сумма всех бонусов],
AVG(Salary/100*BonusPercent) [Средний размер бонуса],
AVG(Salary) [Средний размер ЗП]
FROM Employees
WHERE DepartmentID=3 -- учесть только ИТ-отдел
SELECT
DepartmentID,
PositionID,
BonusPercent,
Salary/100*BonusPercent ,
Salary
FROM Employees
WHERE DepartmentID=3 -- учесть только ИТ-отдел
Идем, дальше. В случае, если агрегатная функция возвращает NULL (например, у всех сотрудников не указано значение Salary), или в выборку не попало ни одной записи, а в отчете, для такого случая нам нужно показать 0, то функцией ISNULL можно обернуть агрегатное выражение: SELECT
SUM(Salary),
AVG(Salary),
-- обрабатываем итог при помощи ISNULL
ISNULL(SUM(Salary),0),
ISNULL(AVG(Salary),0)
FROM Employees
WHERE DepartmentID=10 -- здесь специально указан несуществующий отдел, чтобы запрос не вернул записей
Я считаю, что очень важно понимать назначение каждой агрегатной функции и то каким образом они производят расчет, т.к. в SQL это главный инструмент, который служит для расчета итоговых значений. В данном случае мы рассмотрели, как каждая агрегатная функция ведет себя самостоятельно, т.е. она применялась к значениям всего набора записей полученным командой SELECT. Дальше мы рассмотрим, как эти же функции применяются для вычисления итогов по группам, при помощи конструкции GROUP BY. GROUP BY – группировка данныхДо этого мы уже вычисляли итоги для конкретного отдела, примерно следующим образом:SELECT COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- данные только по ИТ отделу А теперь представьте, что нас попросили получить такие же цифры в разрезе каждого отдела. Конечно мы можем засучить рукава и выполнить этот же запрос для каждого отдела. Итак, сказано-сделано, пишем 4 запроса: SELECT "Администрация" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 -- данные по Администрации SELECT "Бухгалтерия" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=2 -- данные по Бухгалтерии SELECT "ИТ" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- данные по ИТ отделу SELECT "Прочие" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL -- и еще не забываем данные по внештатникам В результате мы получим 4 набора данных:
Обратите внимание, что мы можем использовать поля, заданные в виде констант – "Администрация", "Бухгалтерия", … В общем все цифры, о которых нас просили, мы добыли, объединяем все в Excel и отдаем директору. Отчет директору понравился, и он говорит: «а добавьте еще колонку с информацией по среднему окладу». И как всегда это нужно сделать очень срочно. Мда, что делать?! Вдобавок представим еще что отделов у нас не 3, а 15. Вот как раз то примерно для таких случаев служит конструкция GROUP BY: SELECT
DepartmentID,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees
GROUP BY DepartmentID
Мы получили все те же самые данные, но теперь используя только один запрос! Пока не обращайте внимание, на то что департаменты у нас вывелись в виде цифр, дальше мы научимся выводить все красиво. В предложении GROUP BY можно указывать несколько полей «GROUP BY поле1, поле2, …, полеN», в этом случае группировка произойдет по группам, которые образовывают значения данных полей «поле1, поле2, …, полеN». Для примера, сделаем группировку данных в разрезе Отделов и Должностей: SELECT
DepartmentID,PositionID,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID,PositionID
SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL AND PositionID IS NULL SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 AND PositionID=2 -- ... SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 AND PositionID=4 А потом все эти результаты объединяются вместе и отдаются нам в виде одного набора:
Из основного, стоит отметить, что в случае группировки (GROUP BY), в перечне колонок в блоке SELECT:
И демонстрация всего сказанного: SELECT
"Строка константа" Const1, -- константа в виде строки
1 Const2, -- константа в виде числа
-- выражение с использованием полей участвуещих в группировке
CONCAT("Отдел № ",DepartmentID) ConstAndGroupField,
CONCAT("Отдел № ",DepartmentID,", Должность № ",PositionID) ConstAndGroupFields,
DepartmentID, -- поле из списка полей участвующих в группировке
-- PositionID, -- поле учавствующее в группировке, не обязательно дублировать здесь
COUNT(*) EmplCount, -- кол-во строк в каждой группе
-- остальные поля можно использовать только с агрегатными функциями: COUNT, SUM, MIN, MAX, …
SUM(Salary) SalaryAmount,
MIN(ID) MinID
FROM Employees
GROUP BY DepartmentID,PositionID -- группировка по полям DepartmentID,PositionID
Так же стоит отметить, что группировку можно делать не только по полям, но также и по выражениям. Для примера сгруппируем данные по сотрудникам, по годам рождения: SELECT CONCAT("Год рождения - ",YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday) Рассмотрим пример с более сложным выражением. Для примера, получим градацию сотрудников по годам рождения: SELECT
CASE
WHEN YEAR(Birthday)>=2000 THEN "от 2000"
WHEN YEAR(Birthday)>=1990 THEN "1999-1990"
WHEN YEAR(Birthday)>=1980 THEN "1989-1980"
WHEN YEAR(Birthday)>=1970 THEN "1979-1970"
WHEN Birthday IS NOT NULL THEN "ранее 1970"
ELSE "не указано"
END RangeName,
COUNT(*) EmplCount
FROM Employees
GROUP BY
CASE
WHEN YEAR(Birthday)>=2000 THEN "от 2000"
WHEN YEAR(Birthday)>=1990 THEN "1999-1990"
WHEN YEAR(Birthday)>=1980 THEN "1989-1980"
WHEN YEAR(Birthday)>=1970 THEN "1979-1970"
WHEN Birthday IS NOT NULL THEN "ранее 1970"
ELSE "не указано"
END
Т.е. в данном случае группировка делается по предварительно вычисленному для каждого сотрудника CASE-выражению: SELECT ID, CASE WHEN YEAR(Birthday)>=2000 THEN "от 2000" WHEN YEAR(Birthday)>=1990 THEN "1999-1990" WHEN YEAR(Birthday)>=1980 THEN "1989-1980" WHEN YEAR(Birthday)>=1970 THEN "1979-1970" WHEN Birthday IS NOT NULL THEN "ранее 1970" ELSE "не указано" END FROM Employees
Ну и конечно же вы можете объединять в блоке GROUP BY выражения с полями: SELECT DepartmentID, CONCAT("Год рождения - ",YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday),DepartmentID -- порядок может не совпадать с порядком их использования в блоке SELECT ORDER BY DepartmentID,YearOfBirthday -- напоследок мы можем применить к результату сортировку Вернемся к нашей изначальной задаче. Как мы уже знаем, отчет очень понравился директору, и он попросил нас делать его еженедельно, дабы он мог мониторить изменения по компании. Чтобы, не перебивать каждый раз в Excel цифровое значение отдела на его наименование, воспользуемся знаниями, которые у нас уже есть, и усовершенствуем наш запрос: SELECT
CASE DepartmentID
WHEN 1 THEN "Администрация"
WHEN 2 THEN "Бухгалтерия"
WHEN 3 THEN "ИТ"
ELSE "Прочие"
END Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees
GROUP BY DepartmentID
ORDER BY Info -- добавим для большего удобства сортировку по колонке Info
Но ничего, со временем, мы научимся делать все красиво, чтобы выборка у нас не зависела от появления в БД новых данных, а была динамической. Немного забегу вперед, чтобы показать к написанию каких запросов мы стремимся прийти: SELECT ISNULL(dep.Name,"Прочие") DepName, COUNT(DISTINCT emp.PositionID) PositionCount, COUNT(*) EmplCount, SUM(emp.Salary) SalaryAmount, AVG(emp.Salary) SalaryAvg -- плюс выполняем пожелание директора FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID GROUP BY emp.DepartmentID,dep.Name ORDER BY DepName В общем, не переживайте – все начинали с простого. Пока вам просто нужно понять суть конструкции GROUP BY. Напоследок, давайте посмотрим каким образом можно строить сводные отчеты при помощи GROUP BY. Для примера выведем сводную таблицу, в разрезе отделов, так чтобы была подсчитана суммарная заработная плата, получаемая сотрудниками в разбивке по должностям: SELECT
DepartmentID,
SUM(CASE WHEN PositionID=1 THEN Salary END) [Бухгалтера],
SUM(CASE WHEN PositionID=2 THEN Salary END) [Директора],
SUM(CASE WHEN PositionID=3 THEN Salary END) [Программисты],
SUM(CASE WHEN PositionID=4 THEN Salary END) [Старшие программисты],
SUM(Salary) [Итого по отделу]
FROM Employees
GROUP BY DepartmentID
Можно конечно переписать и при помощи IIF: SELECT DepartmentID, SUM(IIF(PositionID=1,Salary,NULL)) [Бухгалтера], SUM(IIF(PositionID=2,Salary,NULL)) [Директора], SUM(IIF(PositionID=3,Salary,NULL)) [Программисты], SUM(IIF(PositionID=4,Salary,NULL)) [Старшие программисты], SUM(Salary) [Итого по отделу] FROM Employees GROUP BY DepartmentID Но в случае с IIF нам придется явно указывать NULL, которое возвращается в случае невыполнения условия. В аналогичных случаях мне больше нравится использовать CASE без блока ELSE, чем лишний раз писать NULL. Но это конечно дело вкуса, о котором не спорят. И давайте вспомним, что в агрегатных функциях при агрегации не учитываются NULL значения. Для закрепления, сделайте самостоятельный анализ полученных данных по развернутому запросу: SELECT
DepartmentID,
CASE WHEN PositionID=1 THEN Salary END [Бухгалтера],
CASE WHEN PositionID=2 THEN Salary END [Директора],
CASE WHEN PositionID=3 THEN Salary END [Программисты],
CASE WHEN PositionID=4 THEN Salary END [Старшие программисты],
Salary [Итого по отделу]
FROM Employees
И еще давайте вспомним, что если вместо NULL мы хотим увидеть нули, то мы можем обработать значение, возвращаемое агрегатной функцией. Например: SELECT
DepartmentID,
ISNULL(SUM(IIF(PositionID=1,Salary,NULL)),0) [Бухгалтера],
ISNULL(SUM(IIF(PositionID=2,Salary,NULL)),0) [Директора],
ISNULL(SUM(IIF(PositionID=3,Salary,NULL)),0) [Программисты],
ISNULL(SUM(IIF(PositionID=4,Salary,NULL)),0) [Старшие программисты],
ISNULL(SUM(Salary),0) [Итого по отделу]
FROM Employees
GROUP BY DepartmentID
GROUP BY в скупе с агрегатными функциями, одно из основных средств, служащих для получения сводных данных из БД, ведь обычно данные в таком виде и используются, т.к. обычно от нас требуют предоставления сводных отчетов, а не детальных данных (простыней). И конечно же все это крутится вокруг знания базовой конструкции, т.к. прежде чем что-то подытожить (агрегировать), вам нужно первым делом это правильно выбрать, используя «SELECT … WHERE …». Важное место здесь имеет практика, поэтому, если вы поставили целью понять язык SQL, не изучить, а именно понять – практикуйтесь, практикуйтесь и практикуйтесь, перебирая самые разные варианты, которые только сможете придумать. На начальных порах, если вы не уверены в правильности полученных агрегированных данных, делайте детальную выборку, включающую все значения, по которым идет агрегация. И проверяйте правильность расчетов вручную по этим детальным данным. В этом случае очень сильно может помочь использование программы Excel. Допустим, что вы дошли до этого моментаДопустим, что вы бухгалтер Сидоров С.С., который решил научиться писать SELECT-запросы.Допустим, что вы уже успели дочитать данный учебник до этого момента, и уже уверено пользуетесь всеми вышеперечисленными базовыми конструкциями, т.е. вы умеете:
Да, но они не учли, что вы пока не умеете строить запросы из нескольких таблиц, а только из одной, т.е. вы не умеете делать что-то вроде такого: SELECT
emp.*, -- вернуть все поля таблицы Employees
dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments
pos.Name PositionName -- и еще добавить поле Name из таблицы Positions
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
И так, как же можно воспользоваться вашими текущими знаниями и получить при этом еще более продуктивные результаты?! Воспользуемся силой коллективного разума – идем к программистам, которые работают у вас, т.е. к Андрееву А.А., Петрову П.П. или Николаеву Н.Н., и попросим кого-нибудь из них написать для вас представление (VIEW или просто «Вьюха», так они даже, думаю, быстрее поймут вас), которое помимо основных полей из таблицы Employees, будет еще возвращать поля с «Названием отдела» и «Названием должности», которых вам так недостает сейчас для еженедельного отчета, которым вас загрузил Иванов И.И. Т.к. вы все грамотно объяснили, то ИТ-шники, сразу же поняли, что от них хотят и создали, специально для вас, представление с названием ViewEmployeesInfo. Представляем, что вы следующей команды не видите, т.к. это делают ИТ-шники: CREATE VIEW ViewEmployeesInfo AS SELECT emp.*, -- вернуть все поля таблицы Employees dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments pos.Name PositionName -- и еще добавить поле Name из таблицы Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID Т.е. для вас весь этот, пока страшный и непонятный, текст остается за кадром, а ИТ-шники дают вам только название представления «ViewEmployeesInfo», которое возвращает все вышеуказанные данные (т.е. то что вы у них просили). Вы теперь можете работать с данным представлением, как с обычной таблицей: SELECT *
FROM ViewEmployeesInfo
SELECT
DepartmentName,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg
FROM ViewEmployeesInfo emp
GROUP BY DepartmentID,DepartmentName
ORDER BY DepartmentName
Т.е. для вас в данном случае, будто бы ничего и не поменялось, вы продолжаете так же работать с одной таблицей (только уже правильнее сказать с представлением ViewEmployeesInfo), которое возвращает все необходимые вам данные. Благодаря помощи ИТ-шников, детали по добыванию DepartmentName и PositionName остались для вас в черном ящике. Т.е. представление для вас выглядит так же, как и обычная таблица, считайте, что это расширенная версия таблицы Employees. Давайте для примера еще сформируем ведомость, чтобы вы убедились, что все действительно так как я и говорил (что вся выборка идет из одного представления): SELECT
ID,
Name,
Salary
FROM ViewEmployeesInfo
WHERE Salary IS NOT NULL
AND Salary>0
ORDER BY Name
Использование представлений в некоторых случаях, дает возможность значительно расширить границы пользователей, владеющих написанием базовых SELECT-запросов. В данном случае представление, представляет собой плоскую таблицу со всеми необходимыми пользователю данными (для тех, кто разбирается в OLAP, это можно сравнить с приближенным подобием OLAP-куба с фактами и измерениями). Вырезка с википедии. Хотя SQL и задумывался как средство работы конечного пользователя, в конце концов он стал настолько сложным, что превратился в инструмент программиста. Как видите, уважаемые пользователи, язык SQL изначально задумывался, как инструмент для вас. Так что, все в ваших руках и желании, не отпускайте руки. HAVING – наложение условия выборки к сгруппированным даннымСобственно, если вы поняли, что такое группировка, то с HAVING ничего сложного нет. HAVING – чем-то подобен WHERE, только если WHERE-условие применяется к детальным данным, то HAVING-условие применяется к уже сгруппированным данным. По этой причине в условиях блока HAVING мы можем использовать либо выражения с полями, входящими в группировку, либо выражения, заключенные в агрегатные функции.Рассмотрим пример: SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000
Т.е. данный запрос вернул нам сгруппированные данные только по тем отделам, у которых сумма ЗП всех сотрудников превышает 3000, т.е. «SUM(Salary)>3000».
Т.е. здесь в первую очередь происходит группировка и вычисляются данные по всем отделам: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. получаем сгруппированные данные по всем отделам А уже к этим данным применяется условие указанно в блоке HAVING: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. получаем сгруппированные данные по всем отделам HAVING SUM(Salary)>3000 -- 2. условие для фильтрации сгруппированных данных В HAVING-условии так же можно строить сложные условия используя операторы AND, OR и NOT: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х
Как можно здесь заметить агрегатная функция (см. «COUNT(*)») может быть указана только в блоке HAVING. Соответственно мы можем отобразить только номер отдела, подпадающего под HAVING-условие: SELECT DepartmentID FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х Пример использования HAVING-условия по полю включенного в GROUP BY: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. сделать группировку HAVING DepartmentID=3 -- 2. наложить фильтр на результат группировки Это только пример, т.к. в данном случае проверку логичнее было бы сделать через WHERE-условие: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- 1. провести фильтрацию детальных данных GROUP BY DepartmentID -- 2. сделать группировку только по отобранным записям Т.е. сначала отфильтровать сотрудников по отделу 3, и только потом сделать расчет. Примечание. На самом деле, несмотря на то, что эти два запроса выглядят по-разному оптимизатор СУБД может выполнить их одинаково. Думаю, на этом рассказ о HAVING-условиях можно окончить. Подведем итогиСведем данные полученные во второй и третьей части и рассмотрим конкретное месторасположение каждой изученной нами конструкции и укажем порядок их выполнения:
Конечно же, вы так же можете применить к сгруппированным данным предложения DISTINCT и TOP, изученные во второй части. Эти предложения в данном случае применятся к окончательному результату: SELECT
TOP 1 -- 6. применится в последнюю очередь
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000
ORDER BY DepartmentID -- 5. сортировка результата
Как получились данные результаты проанализируйте самостоятельно. ЗаключениеОсновная цель которую я ставил в данной части – раскрыть для вас суть агрегатных функций и группировок.Если базовая конструкция позволяла нам получить необходимые детальные данные, то применение агрегатных функций и группировок к этим детальным данным, дало нам возможность получить по ним сводные данные. Так что, как видите здесь все важно, т.к. одно опирается на другое – без знания базовой конструкции мы не сможем, например, правильно отобрать данные, по которым нам нужно просчитать итоги. Здесь я намеренно стараюсь показывать только основы, чтобы сосредоточить внимание начинающих на самых главных конструкциях и не перегружать их лишней информацией. Твердое понимание основных конструкций (о которых я еще продолжу рассказ в последующих частях) даст вам возможность решить практически любую задачу по выборке данных из РБД. Основные конструкции оператора SELECT применимы в таком же виде практически во всех СУБД (отличия в основном состоят в деталях, например, в реализации функций – для работы со строками, временем, и т.д.). В последующем, твердое знание базы даст вам возможность самостоятельно легко изучить разные расширения языка SQL, такие как:
Если вы делаете первые шаги в SQL, то сосредоточьтесь в первую очередь, именно на изучении базовых конструкций, т.к. владея базой, все остальное вам понять будет гораздо легче, и к тому же самостоятельно. Вам в первую очередь, как бы нужно объемно понять возможности языка SQL, т.е. какого рода операции он вообще позволяет совершить над данными. Донести до начинающих информацию в объемном виде – это еще одна из причин, почему я буду показывать только самые главные (железные) конструкции. Удачи вам в изучении и понимании языка SQL. Часть четвертая - But the Oracle CASE statement is even better. The Oracle 8i release introduced the CASE expression. The Oracle CASE statements can do all that DECODE does plus lot of other things including IF-THEN analysis, use of any comparison operator and checking multiple conditions, all in a SQL query itself. Moreover, using the CASE function, multiple conditions provided in separate SQL queries can be combined into one, thus avoiding multiple statements on the same table (example given below). The function is available from Oracle 8i onwards. Oracle case statement basic syntaxOracle CASE expression syntax is similar to an IF-THEN-ELSE statement. Oracle checks each condition starting from the first condition (left to right). When a particular condition is satisfied (WHEN part) the expression returns the tagged value (THEN part). If none of the conditions are matched, the value mentioned in the ELSE part is returned. The ELSE part of the expression is not mandatory-- CASE expression will return null if nothing is satisfied. Here is the basic syntax of an Oracle CASE When statement: Case when ExamplesThe following examples will make the use of CASE expression more clear, using Oracle CASE select statements. E.g.: Returning categories based on the salary of the employee. Select sal, case when sal < 2000 then "category 1" E.g.: The requirement is to find out the count of employees for various conditions as given below. There are multiple ways of getting this output. Five different statements can be written to find the count of employees based on salary and commission conditions, or a single select having column-level selects could be written. Select count(1) select count(1) select count(1) select count(1) select count(1) Select (select count(1) With CASE expression, the above multiple statements on the same table can be avoided using Oracle select case. Select count(case when sal < 2000 and comm is not null then 1 Select count(case when sal < 2000 and comm is not null then 1 E.g.: CASE expression can also be nested. Select (case when qty_less6months < 0 and qty_6to12months < 0 then E.g.: The data types of the returned values should be the same. In the example below, one argument is assigned a numeric value resulting in an error. SQL> select sal, case when sal < 2000 then "category 1"  Публикации
|






















